
The definitive SEO Checklist for eCommerce
The competition in the eCommerce sector is extremely tough—especially when it comes to SEO. And even a small mistake can put the months of your effort to danger and ruin your performance.
Although nobody is safe from making mistakes—not even the biggest companies in the world—implementing protective measures can help you avoid losing visitors and decreasing profit.
That’s why you should keep an eye on all the aspects listed below that are vital for your overall SEO success.
Preventing thin and duplicate content
Thin content is content that adds little to no value for your visitor. Thin content comes in many forms:
- Pages that have no body content
- Pages that have little body content, say 50 words or less
- Pages that have identical content (also called duplicate content)
- Pages that have nearly identical content (also called near duplicate content)
If pages aren't significantly different from one another, search engines may choose not to rank these pages highly or even ignore them completely. You'll end up competing with your own pages.
Having a lot of thin content is also a signal to search engines that your site isn't in good shape, and may limit your SEO success.
Common causes:
- Product filters
- Faceted navigation
- Pagination
- Preferred amount of products per page
- Sorting
- Product variants
- Having products in multiple categories
Fortunately, there are good countermeasures for thin content at your disposal.
Product filters
Upon interacting with product filters you drill down to a subset of products. From a user's point of view this is great: define search criteria and quickly navigate to a desired product. Quick and easy.
eCommerce websites save these search criterions in the URLURL
The term URL is an acronym for the designation "Uniform Resource Locator".
Learn more, making it easy to go back to it or share it with others. so they can easily go back to it, or share it with others. And this is where duplicate contentDuplicate Content
Duplicate content refers to several websites with the same or very similar content.
Learn more comes in: you can generate a virtually unlimited number of different URLs with all of the filter criteria.
Unless you tell them not to, search engines will crawl these pages. You don't want these pages showing up in the search results but search engines could nonetheless end up spending their valuable crawling time on them. For each domain, search engines have a so-called crawl budget—this is the amount of attention they can give your websiteWebsite
A website is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more.
Ideally, you want them to be spending it on pages that you actually want to show up in the search engineSearch Engine
A search engine is a website through which users can search internet content.
Learn more result pagePage
See Websites
Learn more (SERP).
Best practices:
Prevent search engines from accessing filtered URLs by restricting their access to them. This can be achieved by adding a disallow using your robots.txt file. Find out what URL pattern occurs in each of the filtered URLs and add a Disallow directive for those URLs.
We often see URLs like www.example.com/product-category/?filter=...
You can take away the confusion by making sure search engines never reach those filtered URLs by adding a Disallow directive to your robots.txtRobots.txt
Robots.txt file is a text file that can be saved to a website’s server.
Learn more file:
Disallow /*?filter=*Faceted navigation
Faceted navigation enables you to drill down to a subset of the products in a category.
Take for instance the product category "Televisions". Facets of this category may be subcategories like "LCD Televisions" and "Plasma Televisions".
Best practices:
Often, you want your faceted pages to be indexed. It's important that search engines can distinguish between the different facets, so make sure to include body content on these pages.
Pagination

Product categories with a lot of products are often paginated. A total of 300 products may be divided over 10 separate pages. These pages are all very similar. The only difference being the products shown. For search engines this is basically the same content, only reshuffled.
Search engines consider this thin content. Thin content only confuses search engines, and is therefore often disregarded by them. To avoid this, you want to let search engines know that these 10 paginated pages are in fact a sequence of pages, related to one another.
Best practices:
You can inform search engines that you're using pagination by clearly defining the relationship between these pages. This is done using the links rel="next" and rel="prev". It's recommended paginated pages have a self-referencing canonical URL.
Example:
Page 1 only has a next page. These are the relations that need to be defined in the source:
<link rel="canonical" href="https://www.example.com/page-1/" />
<link rel="next" href="https://www.example.com/page-2/" />Page 2 has a link to the previous page, and to the next page:
<link rel="canonical" href="https://www.example.com/page-2/" />
<link rel="prev" href="https://www.example.com/page-1/" />
<link rel="next" href="https://www.example.com/page-3/" />Page 3 only has a link to the previous page because it's the last one in the sequence.
<link rel="canonical" href="https://www.example.com/page-3/" />
<link rel="prev" href="https://www.example.com/page-2/" />Preferred amount of products per page
A lot of eCommerce websites offer users the possibility to choose how many products are displayed on each page. Often you'll see something like this:
- 12
- 24
- 36
Based on what a visitor chooses, the website generates three new URLs:
www.example.com/product-category/?amount=12
www.example.com/product-category/?amount=24
www.example.com/product-category/?amount=36So now there are 3 other versions of the original page;
www.example.com/product-category/This is considered duplicate content and can therefore cause problems. Search engines will find all four of the pages and be confused about which page to serve.
Best practices:
In the scenario above, adding the following directive to your robots.txt file fixes this issue:
Disallow /*?amount=*Sorting
Sorting is a popular feature on product category pages. For example, it enables users to sort based on price. For a user this is a very useful feature, but if not implemented correctly, this can lead to confused search engines.
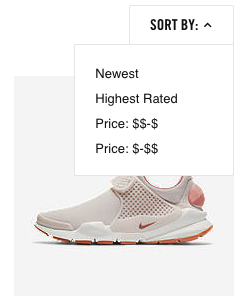
Imagine this: www.example.com/product-category/ - regular overview of products www.example.com/product-category/?sort=priceHigh - overview of products sorted by price, from high to low.www.example.com/product-category/?sort=priceLow - overview of products sorted by price, from low to high.
These three URLs show the same products, just in a different order. This leads to duplicate content and should therefore be dealt with appropriately.
Best practices:
Exclude URLs used for sorting products through your robots.txt file. Adding the following directive to your robots.txt file fixes this for the example above:
Disallow /*?sort=*Product variants
Products such as clothing are often available in multiple sizes and colours. One shoe model may have 32 variants (8 sizes with 4 colours each). We call these product variant pages.
Often these product variant pages don't contain a sufficient amount of unique body content and only the photos are different, so for search engines these products are very similar. This means more duplicate content.
Example:
www.example.com/product-category/product/- main product pagewww.example.com/product-category/product/variant-s/- product in size Swww.example.com/product-category/product/variant-m/- product in size Mwww.example.com/product-category/product/variant-l/- product in size Lwww.example.com/product-category/product/variant-xl/- product in size XL
Best practices:
If you are not going to write sufficient unique body content for any of the product variant pages, prevent duplicate content by canonicalizing URLs 2-5 to www.example.com/product-category/product/.
Having products in multiple categories
In eCommerce, it's also quite common to have products that fall under multiple categories.
Take car batteries, for example. Your batteries are categorized based on voltage and amperage levels, as well as on what car models they work in. You can easily find yourself finding one specific battery through 5 different paths, meaning that for a lot of eCommerce websites, each battery would have 5 URLs, as well. The result? You guessed it—more duplicate content.
Best practices:
Make sure that if a product is in multiple categories, one is marked as its primary category. The primary category defines the URL which you want this product to be indexed at. So if you have a product that's available in four categories you may have the following URLs:
www.example.com/audi/battery/- product with primary product category URL.www.example.com/volkswagen/battery/- product in different product categorywww.example.com/voltage/12v/battery/- product in voltage product categorywww.example.com/amerage/60ah/battery/- product in amperage product categorywww.example.com/new/battery/- product in "new products" category
If URL 1 is the primary URL, then URLs 2 - 5 should all have this canonical URL:
<link rel="canonical" href="https://www.example.com/audi/battery/" />Preserve Crawl Budget
Considering that search engines have billions of pages to crawl, it makes sense that they need to prioritize. Combine that with the fact that resources and capabilities of hosting platforms differ a lot per website, together these two factors comprise your overall crawl budget.
Crawl budget is basically the amount of the search engine's attention your website deserves and can handle. Each website has an assigned crawl budget, and you need to spend this crawl budget wisely. You want search engines to focus on pages you want to rank with. When your crawl budget is exhausted, search engines will stop crawling and return at a later stage. Having your crawl budget spent on pages that search engines can't indexIndex
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine’s index, users will not be able to find it.
Learn more, or on pages you don't want search engines to index can drastically hinder your SEO strategy.
Let's say you have 30,000 pages that are accessible to search engines. On top of that, there are an additional 1,000 pages that deliver a 404 message and another 9,000 pages redirecting to other pages. This leaves us with a grand total of 40,000 pages that search engines can find. On top of that, of those 40,000 pages, only 5,000 of them are indexable for search engines.
So what's wrong with this picture? Only 12.50% (5,000/40,000) of your pages should show up in search engines. Theoretically, search engines would focus 87,50% of their attention on pages that you don't want them to find in the first place. This is a lot of wasted crawl budget.
Best practices:
- Control crawl budget using your robots.txt file. Restrict search engines from accessing sections that are of no concern to them.
- Update or remove links to avoid linking to pages that are redirected (3xx), cannot be found (4xx), or return server errors (5xx).
- Decreasing page load time of your website enables search engines to crawl more pages within the budget allocated to your domain.
Mobile-friendliness
Search engines are rewarding websites that provide great user experience more and more, and mobile-friendliness plays an important part in that.
In late-2015, the amount of mobile searches on Google surpassed the amount of desktop searches. And that number has continued to grow ever since. Mobile-friendliness isn't just important from an SEO point of view—if you want to have a successful eCommerce website, appealing to mobile users is crucial.
The two most common ways to accommodate mobile visitors is through:
- A responsive design, which means the website automatically adjusts to accommodate the user's device.
- A website dedicated and fully optimized to mobile use. Because it's costly to maintain two websites, this approach is only worth it in cases where the majority of your traffic is from mobile users, and a responsive design would limit your ability to provide adequate service.
Regardless of how you cater to mobile users, it's a good idea to run your website through Google's mobile-friendly testing tool just to be sure everything is set up correctly.
The most popular choice: responsive website?
From an SEO standpoint, having a responsive website is usually your best option to service mobile users. For each page only have one URL to promote. You don't have to worry about consolidating link and relevancy signals across the desktop and mobile versions of your pages, as you would with a separate desktop and mobile version.
Implementing separate desktop and mobile websites
If you do choose to go with two separate, dedicated websites, you want to make the relationship between the two clear so search engines point various device users to the website dedicated to them. On top of that, you don't want any duplicate content issues, considering that both websites show the same information. To facilitate this, search engines came up with the rel="alternate" media="x" attribute. For the sake of ease, let's call it the mobile attribute here on out.
The mobile attribute is part of the <link> tag and let's you define an alternative version of your page.
Don't confuse the mobile attribute with the hreflang attribute which is used for translated versions of your page.
Let's look at an example to demonstrate how the mobile attribute works. Say your desktop website is running on https://www.example.com and your mobile website is running on https://m.example.com.
On the desktop page
In the HTML of a desktop page, define the mobile version of the page:
<link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/">This means that the mobile website should be served when the width of the user's device is less than 640 pixels.
On mobile
In the HTML of a mobile page, define the desktop version of the page:
<link rel="canonical" href="http://www.example.com/">Having the canonical URL there prevents duplicate content.
XML sitemap
Google also supports the mobile attribute through XML sitemaps.
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml">
<url>
<loc>http://www.example.com/</loc>
<xhtml:link rel="alternate" media="only screen and (max-width: 640px)" href="http://m.example.com/" />
</url>
</urlset>Accelerated Mobile Pages (AMP)
While we're talking about mobile-friendliness, it's important to bring up Accelerated Mobile Pages (AMP) as well. The vision behind the AMP project is to deliver a better user experienceUser Experience
User experience (or UX for short) is a term used to describe the experience a user has with a product.
Learn more to mobile users through a mobile-first approach and fast-loading pages.
Best practices:
The important thing to know about AMP is that, by general consensus, it is not recommended for eCommerce websites. The AMP guidelines are often too strict to accommodate all of the functionality you need for visitors to go through the entire checkout process.
In most cases having a responsive design is your best option.
Offer users consistent content and functionality across platforms
Be sure to offer desktop and mobile users the same content and functionality. Google has announced they'll switch to a "mobile-first index" somewhere in 2018, meaning that your mobile website will be leading in the Google algorithm instead of the desktop one.
For responsive or dedicated mobile websites that reduce the amount of content they're showing their mobile users, this is bad news. Google isn't ready to switch to the mobile-first index just yet, but you want to get ready for when they do—and sooner rather than later.
HTTPS
Historically, eCommerce websites have used HTTPS for pages in the checkout process. Several years ago, Google started pushing the adoption of HTTPS across your entire website. Serving your entire website through HTTPS plays a minor role in Google's algorithm, so while it may help a little, it's not going to provide a significant competitive edge in terms of SEO.
A more important reason to adopt HTTPS is its improved security. To hammer this point home, all Google Chrome versions released after January 2017 show a warning in the address bar if websites containing form fields aren't served over a secure connection.
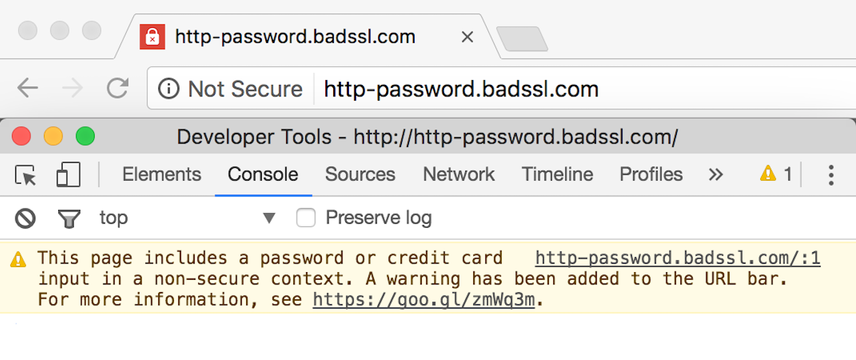
This may scare off potential customers, so here's another reason for you to have your eCommerce website running on HTTPS.
Best practices
- Serve your entire website over HTTPS
- When migrating from HTTP to HTTPS, be sure to do a proper URL migration.
Page speed
Studies have shown that fast-loading pages decrease bounce rates and raise conversionConversion
Conversions are processes in online marketing that lead to a defined conclusion.
Learn more rates. Amazon found that their revenue increased by 1% for every 100ms decrease in load time. Page load time has been a Google ranking factorRanking Factor
The term “Ranking Factors” describes the criteria applied by search engines when evaluating web pages in order to compile the rankings of their search results. Ranking factors can relate to a website’s content, technical implementation, user signals, backlink profile or any other features the search engine considers relevant. Understanding ranking factors is a prerequisite for effective search engine optimization.
Learn more for desktop search since 2010 , and since 2018 for mobile search. But with the introduction of Core Web Vitals, Google's putting even more emphasis on the importance of fast loading pages. So, if you like making money and rank high in Google you need to make sure your pages load fast.
Optimizing for page speed can be a bit of a technical endeavor and there are hundreds of tiny things you can tweak to squeeze every millisecond out of your pages. In practice, focusing on the following three best practices will usually get you 90% of the way there.
Use a Content Delivery Network
Traditionally a single webhost was responsible for hosting the website all by itself. This webhost was located somewhere on our planet, and whenever somebody visited your website from the other side of the globe their connection had quite some ground to cover.
Content Delivery Networks (CDNs) changed this. Instead of hosting your website in a single place, your content is distributed all around the world and when somebody visits your website they connect to the endpoint (called an "edge") that is closest to their location, decreasing the latency to reach your website.
Furthermore CDNs are optimized to serve content fast by caching your pages. By serving a static copy of your pages, they significantly lower the subsequent load time. What's more, CDNs are usually much more capable of handling large traffic volumes. This means that where a severe traffic peak may cause your single-hosted website to slow down or simply crash from overload, CDNs happily keep serving your content.
Nowadays CDNs are both affordable and relatively easy to implement, so there's hardly a reason not to use them.
Optimize your assets
A website doesn't consist of just HTML pages, it also includes a lot of other files, commonly called "assets". Common assets are images, JavaScript (JS) code, and CSS stylesheets. These assets are needed to make sure your website looks and behaves as it should, but if you don't manage them properly, they can also have a negative impact on your page load times.
To prevent slowing down your website, you need to optimize your assets:
- Make sure the images you serve are optimized for the device that's used to visit your website. It doesn't make sense to serve a 4 megapixel image to a mobile visitor.
- Minify and compress your JS and CSS to optimize their size, further reducing load time.
- Load your assets at the right moment. A good example of this are the product photos on your category pages: you don't need to load them immediately, slowing down the rendering of your pages. Instead, load and display them once the rest of the page has been loaded, a technique called "lazy loading". You can do the same with parts of your CSS and JS files: only immediately load what you absolutely need to display the page in the browser, then load the rest.
Use browser caching
Most pages on your website rely on a shared set of assets, such as CSS stylesheets, JS code, and common images such as your website's logo. The problem is that browsers happily re-request any asset they encounter, meaning that when a visitor navigates from one page to another their browser again loads the logo, the CSS stylesheets, and the JS code. Such a waste!
To prevent this, your webserver can send a signal to the browser to keep a cached copy of the assets and re-use them in the future. This is done by sending a cache header together with the asset, instructing the browser to re-use the asset until a certain expiry time.
How to set this up differs from platform to platform, so make sure to inquire with your developer how to implement this on your specific website.
Structured Data
Structured dataStructured Data
Structured data is the term used to describe schema markup on websites. With the help of this code, search engines can understand the content of URLs more easily, resulting in enhanced results in the search engine results page known as rich results. Typical examples of this are ratings, events and much more. The Searchmetrics glossary below contains everything you need to know about structured data.
Learn more refers to applying markup to your pages so search engines understand it better. See it as describing your pages in a language search engines understand. Google, for their part, is the king of understanding and using structured data.
Typically, describing your content is done through schema.org. Schema.org supports a variety of schemas, the most interesting ones for eCommerce websites being:
- Product : to describe products
- Reviews : to describe reviews
- Organization to describe your organization
- Breadcrumbs to signal you use breadcrumbs
- Sitelinks Searchbox to signal you want to show a searchbox in Google's results driven by your own website's search engine.
Price range shown:

Reviews shown:

Best practices
Structured data creates lots of opportunities for creative SEO specialists, so use it to stand out from the competitionCompetition
Businesses generally know who their competitors are on the open market. But are they the same companies you need to fight to get the best placement for your website? Not necessarily!
Learn more.
When implementing structured data, be sure to use Google's structured data testing tool and structured data markup helper .
XML sitemap
An XML sitemap is a file consisting of all of the pages you want search engines to crawl and index. The file is structured using the XML standard, hence the name.
Best practices:
- Make sure your XML sitemap is dynamically generated. When pages are added and removed, your XML sitemap needs to be set up to reflect this.
- Include all of your indexable pages returning HTTP status 200.
- Don't include more than 50,000 URLs in one XML sitemap. It's often recommended to split up XML sitemaps so they don't get too big. In Google Search ConsoleGoogle Search Console
The Google Search Console is a free web analysis tool offered by Google.
Learn more, this enables you to see how many URLs are indexed out of each XML sitemap. - If you have multiple XML sitemaps, be sure to create an XML sitemap index listing all XML sitemaps so search engines can find them easily.
- Reference your XML sitemap(s) in your robots.txt file. This enables search engines to quickly find your XML sitemap.
Hreflang
If you have a multilingual eCommerce website, you need to make sure search engines know which part of the website to serve to which users. For Google and Yandex you can do this using the rel="alternate" hreflang attribute. For the sake of brevity, we'll call the rel="alternate" hreflang attribute simply the hreflang attribute from here on.
The hreflang attribute is part of the <link> tag and let's you define an translated version of your page. Make sure not to confuse the hreflang attribute with the rel="alternate" media attribute which is used to signal a mobile version of your pages.
The hreflang attribute supports both language targetting and a combination of languages and regions.
The hreflang attribute can be defined using:
- HTML link elements in the <head> section
- HTTP header
- XML sitemap
If you're unable to implement the hreflang attribute, you can define your targeting preferences using Google Search Console and Bing Webmaster Tools. If you are able to set up hreflang, be sure your preferences in Google Search Console and Bing Webmaster Tools don't conflict.
The anatomy of the hreflang attribute
The hreflang attribute consists of two parts:
- audience targeting: the definition of the language or a combination of language and geographical location
- What URL to show to your target audience
<link rel="alternate" hreflang="en" href="https://www.example.com/" />When defining the hreflang attribute, you reference each translated version of the page using the hreflang attribute.
You can define a fallback page if no page is available for the audience you're targetting. This is done using the x-default value.
Example
Let's look at an example:
<link rel="alternate" hreflang="en" href="https://www.example.com/" />
<link rel="alternate" hreflang="es" href="https://www.example.com/es/" />
<link rel="alternate" hreflang="x-default" href="https://www.example.com/" />This tells search engines that the English part of your website is available through www.example.com and the Spanish part through www.example.com/es/. The x-default value tells search engines to serve the main website when they're unable to serve the language the visitor is searching in.
Here's a more advanced example with targeting for a combination of languages and geographic locations.
Let's say your website is available in German and you're targeting Germany, Austria, and Switzerland. Let's also assume your German version of the website targeting Germany will be served as your fallback.
<link rel="alternate" href="https://www.example.de/" hreflang="de-DE" />
<link rel="alternate" href="https://www.example.de/at/" hreflang="de-AT" />
<link rel="alternate" href="https://www.example.de/ch/" hreflang="de-CH" />
<link rel="alternate" href="https://www.example.de/" hreflang="x-default" />Best practices
- Make sure your hreflang definitions are bi-directional, meaning each reference should go both ways. For instance, when
https://www.example.de/referenceshttps://www.example.de/at/,https://www.example.de/at/needs to referencehttps://www.example.de/back. - Avoid conflicting targeting. Conflicting targeting could arise when you make mistakes in the references between pages. For instance, when
https://www.example.de/may define that it's targeting just Germany, but ifhttps://www.example.de/at/referenceshttps://www.example.de/for the whole German language there's a conflict. - Define language and region combinations correctly. Always double check if the combination is correct, and that you used them in the right order (language-region).
- Always set the
hreflang="x-default". - Make sure to use the canonical URL together with the
hreflangattribute. Together they work to clearly communicate to search engines the relationships within your website. Only include URLs inhreflangattribute that have a self referencing canonical. - Use absolute URLs when defining the
hreflangattribute. Absolute URLs are less prone to misinterpretation by search engines than relative URLs.
Multilingual websites aren't just about content—the goal here is to provide a complete user experience, including cultural references and currencies.
Conclusion
The eCommerce arena is an extremely competitive one, especially when it comes to SEO. Making a mistake can set your progress back weeks, if not months. This checklist gives you the an arsenal of on-page SEO tactics to take on the competition and solidify your stance on the market.
Whether you're preparing your eCommerce website for launch, or just giving it a facelift, addressing all the issues presented in this article will make sure your launch is a solid one. Then you'll be able to sit back and track the results of all your efforts.
It's important to remember, though, that SEO is a continuous process. If you want it to succeed, your SEO strategy needs regular maintenance, fine-tuning, and even a little tender, loving care. Launching your website, or changes, is just the beginning. After that, the game is on and it's up to you to continuously improve and expand.
Now that you've invested the resources into getting your SEO strategy off to a good start, you'll want to set up monitoring to keep tabs on the health of your website. Enter ContentKing . This real-time SEO monitoring tool is designed to keep your strategy moving forward by tracking your content to help you defuse unforeseen SEO "surprises" and even prevent them in the first place.




