
Crawl budget explained
Crawl budget is the number of pages search engines will crawl on a website within a certain timeframe.
Search engines calculate crawl budget based on crawl limit (how often they can crawl without causing issues) and crawl demand (how often they'd like to crawl a site).
If you’re wasting crawl budget, search engines won’t be able to crawl your website efficiently, which would end up hurting your SEO performance.
What is crawl budget?
Crawl budget is the number of pages search engines will crawl on a websiteWebsite
A website is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more within a certain timeframeFrame
Frames can be laid down in HTML code to create clear structures for a website’s content.
Learn more.
Why do search engines assign crawl budget to websites?
Because they don't have unlimited resources, and they divide their attention across millions of websites. So they need a way to prioritize their crawling effort. Assigning crawl budget to each website helps them do this.
How do they assign crawl budget to websites?
That's based on two factors, crawl limit and crawl demand:
- Crawl limit / host load: how much crawling can a website handle, and what are its owner's preferences?
- Crawl demand / crawl scheduling: which URLs are worth (re)crawling the most, based on its popularity and how often it's being updated.
Crawl budget is a common term within SEO. Crawl budget is sometimes also referred to as crawl space or crawl time.
Is crawl budget just about pages?
It's not actually, for the sake of ease we're talking about pages, but in reality it's about any document that search engines crawl. Some examples of other documents: JavaScript and CSS files, mobile pagePage
See Websites
Learn more variants, hreflang variants and PDF files.
How does crawl limit / host load work in practice?
Crawl limit, or host load if you will, is an important part of crawl budget. Search engines crawlersCrawlers
A crawler is a program used by search engines to collect data from the internet.
Learn more are designed to prevent overloading a web server with requests so they're careful about this.How search engines determine the crawl limit of a website? There are a variety of factors influencing the crawl limit. To name a few:
- Signs of platform in bad shape: how often requested URLs timeout or return server errors.
- The amount of websites running on the host: if your website is running on a shared hosting platform with hundreds of other websites, and you've got a fairly large website the crawl limit for your website is very limited as crawl limit is determined on a host level. You have to share the host's crawl limit with all of the other sites running on it. In this case you'd be way better of on a dedicated server, which will most likely also massively decrease load times for your visitors.
Another thing to consider is having separate mobile and desktop sites running on the same host. They have a shared crawl limit too. So keep this in mind.
How does crawl demand / crawl scheduling work in practice?
Crawl demand, or crawl scheduling, is about determining the worth of re-crawling URLs. Again, many factors influence crawl demand among which:
- Popularity: how many inbound internal and inbound external links a URLURL
The term URL is an acronym for the designation "Uniform Resource Locator".
Learn more has, but also the amount of queries it's ranking for. - Freshness: how often the URL's being updated.
- Type of page: is the type of page likely to change. Take for example a product category page, and a terms and conditions page - which one do you think changes most often and deserves to be crawled more frequently?

Forcing Google's crawlers to come back to your site when there is nothing more important to find (i.e. meaningful change) is not a good strategy and they're pretty smart at working out whether the frequency of these pages changing actually adds value. The best advice I could give is to concentrate on making the pages more important (adding more useful information, making the pages content rich (they will naturally trigger more queries by default as long as the focus of a topic is maintained). By naturally triggering more queries as part of 'recall' (impressions) you make your pages more important and lo and behold: you'll likely get crawled more frequent.
Don't forget: crawl capacity of the system itself
While search engineSearch Engine
A search engine is a website through which users can search internet content.
Learn more crawling systems have massive crawl capacity, at the end of the day it's limited. So in a scenario where 80% of Google's data centers go offline at the same time, their crawl capacity decreases massively and in turn all websites' crawl budget.
Why should you care about crawl budget?
You want search engines to find and understand as many as possible of your indexable pages, and you want them to do that as quickly as possible. When you add new pages and update existing ones, you want search engines to pick these up as soon as possible. The sooner they've indexed the pages, the sooner you can benefit from them.
If you're wasting crawl budget, search engines won't be able to crawl your website efficiently. They'll spend time on parts of your site that don't matter, which can result in important parts of your website being left undiscovered. If they don't know about pages, they won't crawl and indexIndex
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine’s index, users will not be able to find it.
Learn more them, and you won't be able to bring visitors in through search engines to them.
You can see where this is leading to: wasting crawl budget hurts your SEO performance.
Please note that crawl budget is generally only something to worry about if you've got a large website, let's say 10,000 pages and up.

One of the more under-appreciated aspects of crawl budget is load speed. A faster loading website means Google can crawl more URLs in the same amount of time. Recently I was involved with a site upgrade where load speed was a major focus. The new site loaded twice as fast as the old one. When it was pushed live, the number of URLs Google crawled per day went up from 150,000 to 600,000 - and stayed there. For a site of this size and scope, the improved crawl rate means that new and changed content is crawled a lot faster, and we see a much quicker impact of our SEO efforts in SERPs.

A very wise SEO (okay, it was AJ Kohn) once famously said "You are what Googlebot eats.". Your rankings and search visibility are directly related to not only what Google crawls on your site, but frequently, how often they crawl it. If Google misses content on your site, or doesn't crawl important URLs frequently enough because of limited/unoptimized crawl budget, then you are going to have a very hard time ranking indeed. For larger sites, optimizing crawl budget can greatly raise the profile of previously invisible pages. While smaller site need to worry less about crawl budget, the same principles of optimization (speed, prioritization, link structure, de-duplication, etc.) can still help you to rank.
![Paul Shapiro, Head of Technical SEO & SEO Product Management, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/fd312eea58cfe5f254dd24cc22873cef2f57ffbb-450x450.jpg?dpr=1&fit=min&h=100&q=95&w=100)
I mostly agree with Google and for the most part many websites do not have to worry about crawl budget. But for websites that are large-in-size and especially ones that are updated frequently such as publishers, optimizing can make a significant difference.
What is the crawl budget for my website?
Out of all the search engines, Google is the most transparent about their crawl budget for your website.
Crawl budget in Google Search Console
If you have your website verified in Google Search ConsoleGoogle Search Console
The Google Search Console is a free web analysis tool offered by Google.
Learn more, you can get some insight into your website's crawl budget for Google.
Follow these steps:
- Log in to Google Search Console and choose a website.
- Go to
Crawl>Crawl Stats. There you can see the number of pages that Google crawls per day.
During the summer of 2016, our crawl budget looked like this:
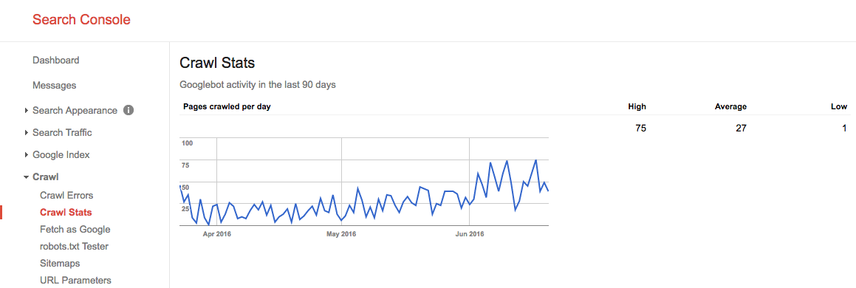
We see here that the average crawl budget is 27 pages / day. So in theory, if this average crawl budget stays the same, you would have a monthly crawl budget of 27 pages x 30 days = 810 pages.
Fast forward 2 years, and look at what our crawl budget is right now:
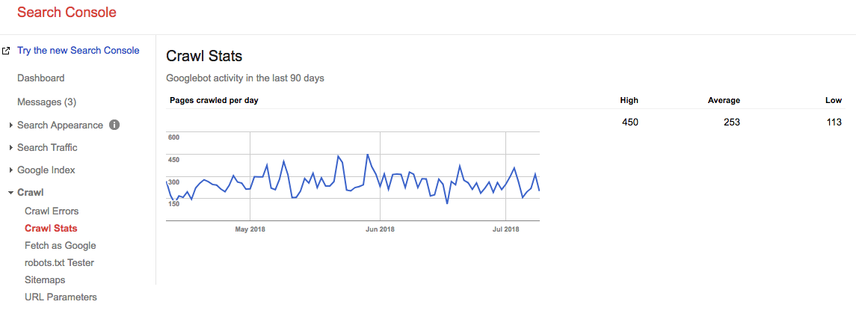
Our average average crawl budget is 253 pages / day, so you could say that our crawl budget went up 10X in 2 years' time.
Go to the source: server logs
It's very interesting to check your server logs to see how often Google's crawlers are hitting your website. It's interesting to compare these statistics to the ones being reported in Google Search Console. It's always better to rely on multiple sources.
How do you optimize your crawl budget?
Optimizing your crawl budget comes down to making sure no crawl budget is wasted. Essentially, fixing the reasons for wasted crawl budget. We monitor thousands of websites; if you were to check each one of them for crawl budget issues, you'd quickly see a pattern: most websites are suffering from the same kind of issues.
Common reasons for wasted crawl budget that we encounter:
- Accessible URLs with parameters: an example of a URL with a parameter is
https://www.example.com/toys/cars?color=black. In this case, the parameter is used to store a visitor's selection in a product filter. - Duplicate content: we call pages that are highly similar, or exactly the same, "duplicate contentDuplicate Content
Duplicate content refers to several websites with the same or very similar content.
Learn more." Examples are: copied pages, internal search resultSearch Result
Search results refer to the list created by search engines in response to a query.
Learn more pages, and tag pages. - Low-quality content: pages with very little content, or pages that don't add any value.
- Broken and redirecting links: broken links are links referencing pages that don't exist anymore, and redirected links are links to URLs that are redirecting to other URLs.
- Including incorrect URLs in XML sitemaps: non-indexable pages and non-pages such as 3xx, 4xx and 5xx URLs shouldn't be included in your XML sitemap.
- Pages with high load time / time-outs: pages that take a long time to load, or don't load at all, have a negative impact on your crawl budget, because it's a sign to search engines that your website can't handle the request, and so they may adjust your crawl limit.
- High numbers of non-indexable pages: the website contains a lot of pages that aren't indexable.
- Bad internal link structure: if your internal link structure isn't set up correctly, search engines may not pay enough attention to some of your pages.
![Jenny Halasz, Head of SEO, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/9025d4aff37a475a4c43326ebd50f8997ee20709-500x500.jpg?dpr=1&fit=min&h=100&q=95&w=100)
I've often said that Google is like your boss. You wouldn't go into a meeting with your boss unless you knew what you were going to talk about, the highlights of your work, the goals of your meeting. In short, you'll have an agenda. When you walk into Google's "office", you need the same thing. A clear site hierarchy without a lot of cruft, a helpful XML sitemap, and quick response times are all going to help Google get to what's important. Don't overlook this often misunderstood element of SEO.

To me, the concept of crawl budget is one of THE key points of technical SEO. When you optimize for crawl budget, everything else falls into place: internal linking, fixing errors, page speed, URL optimization, low-quality content, and more. People should dig into their log files more often to monitor crawl budget for specific URLs, subdomains, directory, etc. Monitoring crawl frequency is very related to crawl budget and super powerful.
Accessible URLs with parameters
In most cases, URLs with parameters shouldn't be accessible for search engines, because they can generate a virtually infinite quantity of URLs. We've written extensively about this type of issue in our article about crawler traps.
URLs with parameters are commonly used when implementing product filters on eCommerce sites. It's fine to use them; just make sure they aren't accessible to search engines.
How can you make them inaccessible to search engine?
- Use your robots.txtRobots.txt
Robots.txt file is a text file that can be saved to a website’s server.
Learn more file to instruct search engines not to access such URLs. If this isn't an option for some reason, use the URL parameter handling settings in Google Search Console and Bing Webmaster Tools to instruct Google and Bing regarding which pages not to crawl. - Add the nofollow attribute value to links on filter links. Please note that as of March 2020, Google may choose to ignore the nofollow. Therefore step 1 is even more important.
Duplicate content
You don't want search engine to spend their time on duplicate content pages, so it's important to prevent, or at the very least minimize, the duplicate content in your site.
How do you do this? By…
- Setting up website redirects for all domain variants (
HTTP,HTTPS,non-WWW, andWWW). - Making internal search result pages inaccessible to search engines using your robots.txt. Here's an example robots.txt for a WordPress website.
- Disabling dedicated pages for images (for example: the infamous image attachment pages in WordPress).
- Being careful around your use of taxonomies such as categories and tags.
Check out some more technical reasons for duplicate content and how to fix them.
Low-quality content
Pages with very little content aren't interesting to search engines. Keep them to a minimum, or avoid them completely if possible. One example of low-quality content is a FAQ section with links to show the questions and answers, where each question and answer is served over a separate URL.
Broken and redirecting links
Broken links and long chains of redirects are dead ends for search engines. Similar to browsers, Google seems to follow a maximum of five chained redirects in one crawl (they may resume crawling it later). It's unclear how well other search engines deal with subsequent redirects, but we strongly advise that you avoid chained redirects entirely and keep the usage of redirects to a minimum.
It's clear that by fixing broken links and redirecting links, you can quickly recover wasted crawl budget. Besides recovering crawl budget, you're also significantly improving a visitor's user experienceUser Experience
User experience (or UX for short) is a term used to describe the experience a user has with a product.
Learn more. Redirects, and chains of redirects in particular, cause longer page load time and thereby hurt the user experience.
To make finding broken and redirecting links easy, we've dedicated special Issues to this within ContentKing.
Go to Issues > Links to find out if you are wasting crawl budgets because of faulty links. Update each link so that it link to an indexable page, or remove the link if it's no longer needed.
Incorrect URLs in XML sitemaps
All URLs included in XML sitemaps should be for indexable pages. Especially with large websites, search engines heavily rely on XML sitemaps to find all your pages. If your XML sitemaps are cluttered with pages that, for instance, don't exist anymore or are redirecting, you're wasting crawl budget. Regularly check your XML sitemap for non-indexable URLs that don't belong in there. Check for the opposite as well: look for pages that are incorrectly excluded from the XML sitemap. The XML sitemap is a great way to help search engines spend crawl budget wisely.
Google Search Console
How to find reports on XML sitemap issues in GSC:
- Log onto Google Search Console
- Click on
Indexing>Sitemaps - Click on the XML sitemap
- Click on
SEE PAGE INDEXING
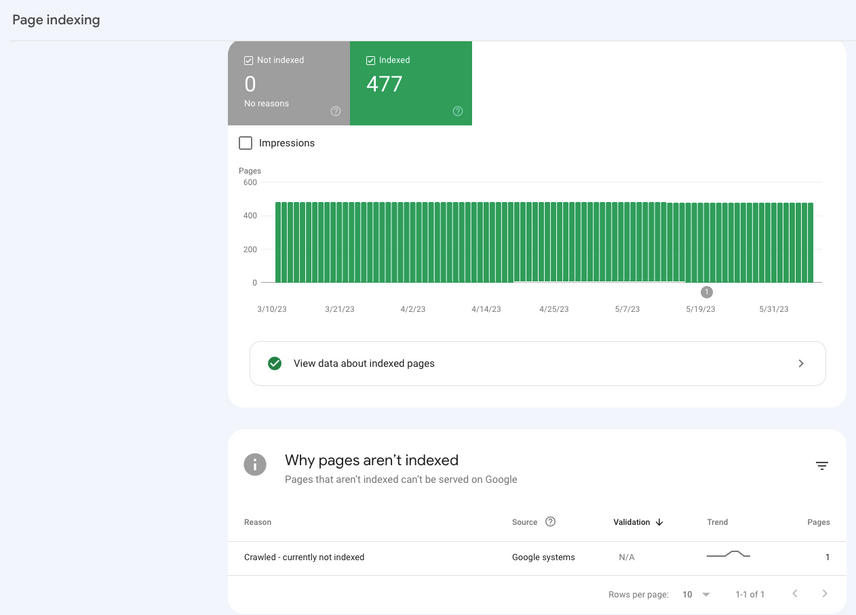
Bing Webmaster Tools
How to find reports on XML sitemap issues in Bing:
- Log onto your Bing Webmaster Tools account
- Click the
Configure My Sitetab - Click the
Sitemapstab
ContentKing
How to find reports on XML sitemap issues using ContentKing:
- Log onto your ContentKing account
- Click the
Issuesbutton - Click the
XML Sitemapbutton - In case of issues with your page you will receive this message:
Page is incorrectly included in XML sitemap
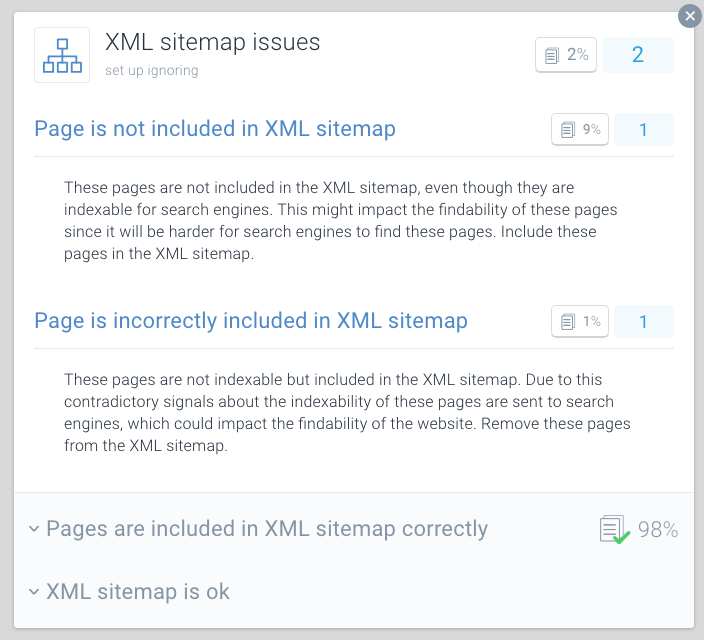
One best practice for crawl-budget optimization is to split your XML sitemaps up into smaller sitemaps. You can for instance create XML sitemaps for each of your website's sections. If you've done this, you can quickly determine if there are any issues going on in certain sections of your website.
Say your XML sitemap for section A contains 500 links, and 480 are indexed: then you're doing pretty good. But if your XML sitemap for section B contains 500 links and only 120 are indexed, that's something to look into. You may have included a lot of non-indexable URLs in the XML sitemap for section B.
Pages with high load times / timeouts
Pages with high load times / timeouts hurt the crawl process
When pages have high load times or they time out, search engines can visit fewer pages within their allotted crawl budget for your website. Besides that downside, high page load times and timeouts significantly hurt your visitor's user experience, resulting in a lower conversionConversion
Conversions are processes in online marketing that lead to a defined conclusion.
Learn more rate.
Page load times above two seconds are an issue. Ideally, your page will loadd in under one second. Regularly check your page load times with tools such as Pingdom , WebPagetest or GTmetrix .
Google reports on page load time in both Google Analytics (under Behavior > Site Speed) and Google Search Console under Crawl > Crawl Stats.
Google Search Console and Bing Webmaster Tools both report on page timeouts. In Google Search Console, this can be found under Settings > Crawl Stats, and in Bing Webmaster Tools, it's under Reports & Data > Crawl Information.
Check regularly to see if your pages are loading fast enough, and take action immediately if they aren't. Fast-loading pages are vital to your online success.
High numbers of non-indexable pages
If your website contains a high number of non-indexable pages that are accessible to search engines, you're basically keeping search engines busy sifting through irrelevant pages.
We consider the following types to be non-indexable pages:
- Redirects (3xx)
- Pages that can't be found (4xx)
- Pages with server errors (5xx)
- Pages that are not indexable (pages that contain the robots noindex directive or canonical URL)
In order to find out if you have a high number of non-indexable pages, look up the total number of pages that crawlers have found within your website and how they break down. You can easily do this using ContentKing:
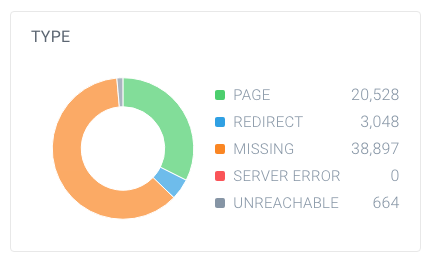
In this example, there are 63,137 URLs found, of which only 20,528 are pages:
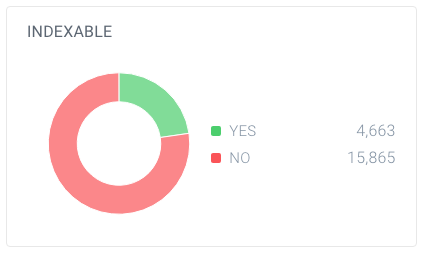
And out of these pages, only 4,663 are indexable for search engines. Only 7.4% of the URLs found by ContentKing can be indexed by search engines. That's not a good ratio, and this website definitely needs to work on that by cleaning up all references to them that are unnecessary, including:
- The XML sitemap (see previous section)
- Links
- Canonical URLs
- Hreflang references
- Pagination references (link rel prev/next)
Bad internal link structure
How pages within your website link to one another plays a big role in crawl budget optimization. We call this the internal link structure of your website. BacklinksBacklinks
Backlinks are links from outside domains that point to pages on your domain; essentially linking back from their domain to yours.
Learn more aside, pages that have few internal linksInternal links
Hyperlinks that link to subpages within a domain are described as "internal links". With internal links the linking power of the homepage can be better distributed across directories. Also, search engines and users can find content more easily.
Learn more get much less attention from search engines than pages that are linked to by a lot of pages.
Avoid a very hierarchical link structure, with pages in the middle having few links. In many cases these pages will not be frequently crawled. It's even worse for pages at the bottom of the hierarchy: because of their limited amount of links, they may very well be neglected by search engines.
Make sure that your most important pages have plenty of internal links. Pages that have recently been crawled typically rank better in search engines. Keep this in mind, and adjust your internal link structure for this.
For example, if you have a blog article dating from 2011 that drives a lot of organic traffic, make sure to keep linking to it from other content. Because you've produced many other blog articles over the years, that article from 2011 is automatically being pushed down in your website's internal link structure.

You usually don't have to worry about the crawl-rate of your important pages. It's usually pages that are new, that you didn't link to, and that people aren't going to that may not be crawled often.
How do you increase your website's crawl budget?
During an interview between Eric Enge and Google's former head of the webspam team Matt Cutts, the relation between authority and crawl budget was brought up:

The best way to think about it is that the number of pages that we crawl is roughly proportional to your PageRank. So if you have a lot of incoming links on your root page, we'll definitely crawl that. Then your root page may link to other pages, and those will get PageRank and we'll crawl those as well. As you get deeper and deeper in your site, however, PageRank tends to decline.
Even though Google has abandoned updating PageRank values of pages publicly, we think (a form of) PageRank is still used in their algorithms. Since PageRank is a misunderstood and confusing term, let's call it page authority. The take-away here is that Matt Cutts basically says: there's a pretty strong relation between page authority and crawl budget.
So, in order to increase your website's crawl budget, you need to increase the authority of your website. A big part of this is done by earning more links from external websites. More information about this can be found in our link building guide.
![Ross Tavendale, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/4582e266c5170a50ed33cfa56135f930db04bc1b-200x200.jpg?dpr=1&fit=min&h=100&q=95&w=100)
When I hear the industry talking about crawl budget, we usually talk about the on-page and technical changes we can make in order to increase the crawl budget over time. However, coming from a link building background, the largest spikes in crawled pages we see in Google Search Console directly relate to when we win big links for our clients.
Frequently asked questions about crawl budget
1. What is crawl budget?
Crawl budget is the number of pages search engines will crawl on a website within a certain timeframe.
2. How do I increase my crawl budget?
Google has indicated there’s a strong relation between page authority and crawl budget. The more authority a page has, the more crawl budget it has. Simply put, to increase your crawl budget, build your page’s authority.
3. What can limit my crawl budget?
Crawl limit, also known as crawl host load, is based on many factors, such as the website’s condition and hosting abilities. Search engine crawlers are set to prevent overloading a web server. If your website returns server errors, or if the requested URLs time out often, the crawl budget will be more limited. Similarly, if your website runs on a shared hosting platform, the crawl limit will be higher as you have to share your crawl budget with other websites running on the hosting.
4. Should I be using canonical URL and meta robots at all?
Yes, and it's important to understand the differences between indexing issues and crawl issues.
The canonical URL and meta robots tags send a clear signal to search engines what page they should show in their index, but it does not prevent them from crawling those other pages.
You can use the robots.txt file and the nofollow link relation for dealing with crawl issues.




