
Meta Robots Tag Guide
Meta robots tags are an essential tool to improve search engine’s crawling and indexing behavior, and to control your snippets in the SERP.
In this article we'll explain how to do this, how interpretation and support differs per search engines and how the meta robots tag relates to the X-Robots-Tag and robots.txt file.
What is the meta robots tag?
The meta robots tag gives site owners power over search engines’ crawling and indexing behavior and how their snippets are served in search engineSearch Engine
A search engine is a website through which users can search internet content.
Learn more result pages (SERPs).
The meta robots tag goes into the <head> section of your HTML and is just one of the meta tags that live there.
Arguably the most well-known meta robots tag is the one telling search engines not to index a page:
<meta name="robots" content="noindexIndex
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine’s index, users will not be able to find it.
Learn more,follow" />
You can provide the same instructions by including them in the HTTP header using the X-Robots-Tag. The X-Robots-Tag is often used to prevent non-HTML content such as PDF and images from being indexed.
Meta robots directives
We prefer to talk about meta robots directives instead of meta robots tags, because calling them “meta robots tags” is incorrect (see “anatomy of the meta element” below).
Meta robots directives are not to be confused with robots.txt directives. These are two different ways of communicating with search engines about different aspects of their crawling and indexing behavior. But they do influence one another , as we’ll see further down the article.
Anatomy of the meta element
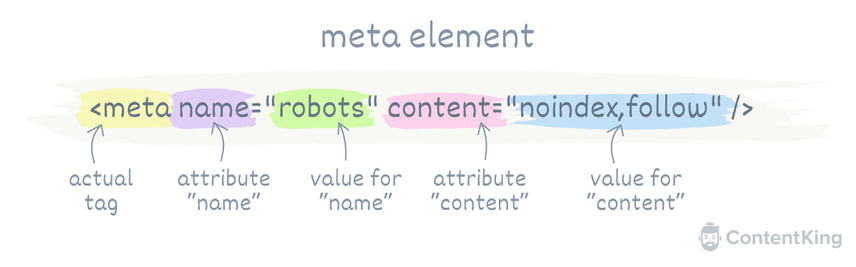
Let’s use the meta robots directive example mentioned above to explain what’s what:
- The entire code snippet is called the
meta element. - The
<metaand/>are the opening and closing tags. - There’s an attribute called
namewith the valuerobots.robotsapplies to all crawlersCrawlers
A crawler is a program used by search engines to collect data from the internet.
Learn more but can be replaced with a specific user-agent. - And then there’s an attribute called
contentwith the valuenoindex,follow.noindex,followcan be replaced with other directives.
Why is it important?
Firstly, meta robots directives give you much-needed control over search engines’ crawling and indexing behavior. Without any direction, search engines will try to crawl and index all the content they come across. That’s their default behavior.
Secondly, search engines will generate a snippet for your URLs when they rank them. They take your meta descriptionMeta Description
The meta description is one of a web page’s meta tags. With this meta information, webmasters can briefly sketch out the content and quality of a web page.
Learn more as input, though they will often instead come up with their own snippet—based on your page’s content—if they think it’ll perform better.
Now, let’s look at a few applications of the meta robots directives in protecting your SEO performance:
- Prevent a duplicate content issue by applying the meta robots
noindexdirective to PPC landing pages and on-site search resultSearch Result
Search results refer to the list created by search engines in response to a query.
Learn more pages. Note that robots directives will not pass on any authority and relevancy like the canonical URL would. - Prevent search engines from indexing content that should never be indexed because you’re providing discounts or some other offer that you don’t want to be available to the entire world.
- Remove sensitive content that has been indexed: if search engines have indexed content they should never have indexed in the first place, apply the meta robots
noindexdirective to remove the content from their indices. You can use the same technique when fixing crawler traps. - Selectively apply the meta robots
noindexdirective to discontinued products to keep providing users with a good user experienceUser Experience
User experience (or UX for short) is a term used to describe the experience a user has with a product.
Learn more.
We deliberately have not listed making sure staging environments don’t get indexed by search engines as a use case.
That's because using HTTP Auth is a much better solution, as it prevents access from both users and search engines and keeps the meta robots noindex directive from carrying over to the production site.
Meta robots syntax explained
Before we dig in deeper, let’s cover some of the basics.
The syntax is not case sensitive
Meta robots directives are not case sensitive, meaning the examples below are all valid:
<meta name="robots" content="noindex,follow" /><meta name="ROBOTS" content="noindex,follow" /><meta name="robots" content="NOINDEX,FOLLOW" />Separating directives with commas for Google
For Google, you need to separate directives with a comma. A space doesn’t cut it:
<meta name="robots" content="noindex follow" />Spaces after commas not required
You’re not required to use spaces after commas between directives. So, the examples below are both valid:
<meta name="robots" content="noindex,follow" /><meta name="robots" content="noindex, follow" />Now, let’s move on to the directives themselves!
Meta robots directives in detail
In this section we’ll cover the most common meta directives you’ll come across in the wild and what exactly they mean. We'll focus primarily on directives support from Google, as they are the dominant search engine.
Here are the directives we'll cover:
Meta robots “all”
By default, search engines will crawl and index any content they come across, unless specified otherwise. If you want to explicitly define that this is allowed, you can do so with the following directive:
<meta name="robots" content="all" />
Meta robots “index”
While not necessary because it’s default behavior, if you want to make it explicit to search engines that they are allowed to index a pagePage
See Websites
Learn more, you can do so with the meta robots directive below.
<meta name="robots" content="index" />
Meta robots “index,follow”
Oftentimes the index directive is combined with the follow directive, leading to:
<meta name="robots" content="index,follow" />
These directives essentially mean the same thing as the one above that only states index, since follow is default search engine behavior as well.
Meta robots “noindex”
The meta robots noindex directive tells search engines not to index a page. Here’s what the meta robots noindex directive looks like:
<meta name="robots" content="noindex" />
The example above tells search engines they shouldn’t index the page, but they should feel free to follow all its links, because it’s not explicitly stated they shouldn’t.
The noindex directive carries a lot of weight, so when search engines find it, they are quick to remove content from their index. The other side of the coin is that it’s tough to get this content re-indexed when for example you’ve accidentally applied the noindex directive.
Meta robots “noindex,follow”
You’ll frequently find meta robots noindex being combined with the follow directive. It tells search engines not to index the page—but that it’s fine to follow the links:
<meta name="robots" content="noindex,follow" />
At the risk of sounding like a broken record, <meta name="robots" content="noindex" /> and <meta name="robots" content="noindex,follow" /> mean the same thing, since follow is default search engine crawler behavior.
Meta robots “noindex,nofollow”
You can also combine the meta robots noindex directive with a nofollow meta directive (not to be confused with the nofollow link attribute):
<meta name="robots" content="noindex,nofollow" />
The noindex,nofollow combination tells search engines not to index the page and not to follow the links on the page, meaning no link authority should be passed on either.
”noindex” becomes “noindex,nofollow” over time
Search engines significantly decrease re-crawling of a noindexed page, essentially leading to a noindex, nofollow situation, because links on a page that doesn’t get crawled are not followed.
Meta robots “none”
The meta robots none directive is actually a shortcut for noindex,nofollow, which we covered just above. Here’s what the meta robots none directive looks like:
<meta name="robots" content="none" />
It’s not used very often, and folks often think it means the exact opposite: index,follow.
So be careful with this one!
Meta robots “noarchive”
The meta robots noarchive directive prevents search engines from presenting a cached version of a page in the SERP. If you don’t specify the noarchive directive, search engines may just go ahead and serve a cached version of the page. So again, this is an opt-out directive.
Here’s what the noarchive directive looks like:
<meta name="robots" content="noarchive" />
It’s frequently combined with other directives though. For example, you’ll commonly see it used together with the noindex and nofollow directives:
<meta name="robots" content="noindex,nofollow,noarchive" />
This means search engines shouldn’t index the page, shouldn’t follow any of its links and shouldn’t cache the page either.
Meta robots “nosnippet”
The meta robots nosnippet directive tells search engines not to show a text snippet (usually drawn from the meta description) or video preview for the page.
Here’s what the nosnippet directive looks like:
<meta name="robots" content="nosnippet" />
If we were to apply the meta robots nosnippet directive to our redirects article, the snippet would then look like this:

Search engines may still show an image thumbnail if they think this results in a better user experience. For Google, this applies to regular Web Search, Google Images, and Google Discover. The nosnippet directive also functions as a noarchive directive.
If the nosnippet directive is not included, Google will generate a text snippet and video preview on its own.
Preventing certain content from being used for a snippet
On Google specifically, you can prevent some of your page’s content from showing up in a snippet by using the data-nosnippet HTML attribute. While it’s not a meta robots directive, it is closely related to them, so we need to touch on this here.
The data-nosnippet HTML attribute can be used on span, div, and section elements. Here’s an example:
<p>This may be shown in a snippet, while
<span data-nosnippet>this will not be shown in a snippet</span>.</p>
Learn more about the data-nosnippet attribute here .
Meta robots “max-snippet”
The meta robots max-snippet directive tells search engines to limit the page’s snippet (generally drawn from the page’s meta description) to a specified number of characters.
Here's an example where the snippet will have a maximum length of 50 characters:
<meta name="robots" content="max-snippet:50" />
Meta robots “max-snippet:0”
When you specify max-snippet:0, you’re telling search engines not to show a snippet—essentially the same as the meta robots nosnippet directive we just described above:
<meta name="robots" content="max-snippet:0" />
Meta robots “max-snippet:-1”
When you specify max-snippet:-1, you’re explicitly telling search engines they can determine the snippet’s length themselves, which is their default behavior:
<meta name="robots" content="max-snippet:-1" />
Impact of the European Copyright Directive
Since October 2019, sites classified as “European press publications” are shown in Google without a snippet by default. You can opt-in to having your snippets shown by using the max-snippet and max-image-preview directives, or you can choose to remove your site from the list of European press publications via Google Search Console . Learn more about this here .
If you’re using the Yoast SEO plugin on WordPress, you’ll find that it automatically opts in when you include the following snippet: <meta name="robots" content="index, follow, max-snippet:-1, max-image-preview:large, max-video-preview:-1" />
Less-important meta robots directives
Now we’ve arrived at the less important meta robots directives, which we’ll only touch on briefly.
What goes for the other meta robots directives goes for these too: if they aren’t defined, search engines will do as they please.
Here’s what the directives signal to search engines:
unavailable_after: "remove a page from your index after a specific date". The date should be specified in a widely adopted format, such as for example ISO 8601 . The directive is ignored if no valid date/time is specified. By default there is no expiration date for content. It’s basically a timednoindexdirective, so be careful when using it.noimageindex: "don’t index the images on this page".max-image-preview: "define a maximum size for the image preview for a page, with possible values:none,standardandlarge".max-video-preview: "define a maximum for the preview length of videos on the page".notranslate: "don't offer a translated version of the page in your search results".
How can you combine meta robots directives?
In addition to being able to combine directives, you can also provide directives to different crawlers. Each crawler will use the sum of the directives provided to them, that is: they stack.
To illustrate how, let’s look at an example:
<meta name="robots" content="nofollow" />
<meta name="googlebot" content="noindex" />These directives are interpreted as follows:
- Google:
noindex,nofollow - Other search engines:
nofollow
How do search engines interpret conflicting directives?
As you can imagine, when you start stacking directives, it’s easy to mess up. If a scenario presents itself where there are conflicting directives, Google will default to the most restrictive one.
Take for example the following directives:
<meta name="robots" content="index" />
<meta name="googlebot" content="noindex" />Verdict: Google will err on the side of caution and not index the page.
But, the way conflicting directives are interpreted can differ among search engines. Let’s take another example:
<meta name="robots" content="index" />
<meta name="robots" content="noindex" />Google will not index this page, but Yandex will do the exact opposite and index it.
So keep this in mind, and make sure that your robots directives work right for the search engines that are important to you.
X-Robots-Tag—the HTTP header equivalent
Non-HTML files such as images and PDF files don’t have an HTML source that you can include a meta robots directive in. If you want to signal your crawling and indexing preferences to search engines for these files, your best bet is to use the X-Robots-Tag HTTP header.
Let’s briefly touch on HTTP headers.
When a visitor or search engine requests a page from a web server, and the page exists, the web server typically responds with three things:
- HTTP Status Code: the three-digit response to the client’s request (e.g.
200 OK). - HTTP Headers: headers containing for example the
content-typethat was returned and instructions on how long the client should cache the response. - HTTP Body: the body (e.g.
HTML,CSS,JavaScriptetc.), which is used to render and display the page in a browser.
The X-Robots-Tag can be included in the HTTP Headers. Here’s a screenshot of a page’s HTTP response headers taken from Chrome Web Inspector, for a page that contains a X-Robots-Tag: noindex:
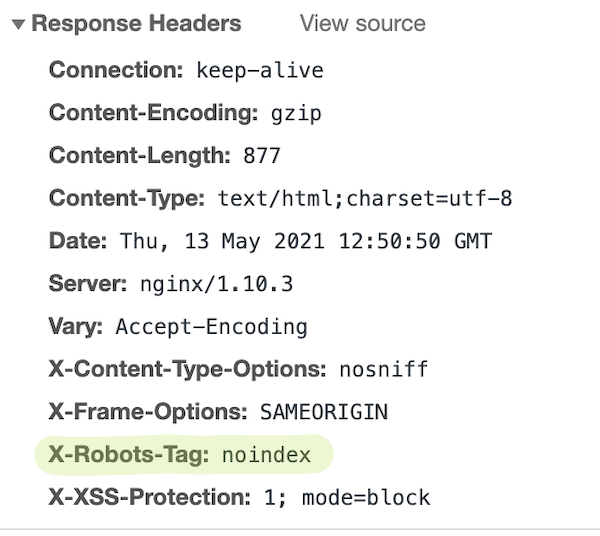
So how does this work in practice?
Configuring X-Robots-Tag on Apache
For example, if you're using the Apache web server, and you’d like to add a noindex,nofollow X-Robots-Tag to the HTTP response for all of your PDF files, add the following snippet to your .htaccess file or httpd.conf file:
<Files ~ "\.pdf$">
Header set X-Robots-Tag "noindex,nofollow"
</Files>Or perhaps you want to make images of file types PNG, JPG, JPEG, and GIF non-indexable:
<Files ~ "\.(png|jpe?g|gif)$">
Header set X-Robots-Tag "noindex"
</Files>Configuring X-Robots-Tag on nginx
Meanwhile on the nginx web server, you need to edit a site’s .conf file.
To remove all PDF files from search engines’ indices across an entire site, use this:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}And to noindex the images, use this:
location ~* \.(png|jpe?g|gif)$ {
add_header X-Robots-Tag "noindex";
}Note that tweaking your web server configuration can negatively impact your entire website’s SEO performance. Unless you're comfortable with making changes to your web server's configuration, it’s best to leave these changes to your server administrator.
Because of this, we highly recommend monitoring your sites with ContentKing . Our platform immediately flags any changes so that you can revert the changes before they have a negative impact on your SEO performance.
SEO best practices for robots directives
Stick to these best practices around robots directives:
- Avoid conflicting robots directives: avoid using both meta robots and X-Robots-Tag directives to signal your crawling and indexing preferences for your pages, as it’s easy to mess up and send conflicting instructions. It’s fine to use meta robots directives on pages and X-Robots-Tag for your images and PDFs though—just make sure you're not using both methods of delivering robots directive instructions on the same file.
- Don’t disallow content with important robots directives: if you disallow content using your robots.txtRobots.txt
Robots.txt file is a text file that can be saved to a website’s server.
Learn more, search engines won’t be able to pick up that content’s preferred robots directives. Say for example you apply thenoindexdirective to a page, and go on todisallowaccess to that same page. Search engines won’t be able to see thenoindex, and they may still keep the page in their index for a long time. - Don’t combine noindex directive with canonical URL: a page that has both a
noindexdirective and a canonical to another page is confusing for search engines. In rare cases, this results in thenoindexbeing carried over to the canonical target. Learn more. - Don’t apply noindex directive to paginated pages: because search engines (Google especially) understand paginated pages well, they treat them differently and won’t see them as duplicate contentDuplicate Content
Duplicate content refers to several websites with the same or very similar content.
Learn more. And keep in mind that in practice, over time anoindexdirective becomes anoindex,nofollow, closing the door on a discovery path for the content that’s linked through paginated pages. Learn more. - No hreflang to pages with noindex:
hreflangsignals to search engines which content variants are available to different audiences, sending a signal that these need to be indexed. Therefore, avoid referencing pages that have anoindexdirective. - Don’t include pages with noindex in XML sitemap: pages that shouldn’t be indexed, shouldn’t be included in your XML sitemap either, since the XML sitemap is used to signal to search engines which pages they should crawl and index.
Meta robots vs X-Robots-Tag vs Robots.txt
The Meta robots directives, X-Robots-Tag and robots.txt all have their own unique uses. To summarize what we’ve covered so far, here’s what they can be used for:
Meta robots | X-Robots-Tag | Robots.txt | |
|---|---|---|---|
Used on | HTML files | Any file | Any file |
Scope | Per page | Unlimited | Unlimited |
Influences crawling | nofollow | nofollow | |
Influences indexing | * | ||
Consolidates signals |
* Content that’s disallowed in the robots.txt generally will not get indexed. But in rare cases, this still can happen.
Support across search engines
It’s not just the interpretation of conflicting robots directives that can differ per search engine. The directives supported and the support for their delivery method (HTML or HTTP Header) can vary too. If a cell in the table below has a green checkmark (✅ ), both HTML and HTTP header implementations are supported. If there’s a red cross (❌ ), none are supported. If only one is supported, it’s explained.
Directive | Bing/Yahoo | Yandex | |
|---|---|---|---|
all | Only meta robots | ||
index | Only meta robots | ||
follow | Only meta robots | ||
noindex | |||
nofollow | |||
none | |||
noarchive | |||
nosnippet | |||
max-snippet |
And now, on to the less important ones:
Directive | Bing/Yahoo | Yandex | |
|---|---|---|---|
unavailable_after | |||
noimageindex | |||
max-image-preview | |||
max-video-preview | |||
notranslate |
Wrapping up and moving on
Solid technical SEO is all about sending search engines the right signals. And the meta robots directive is just one of those signals.
So continue learning how to take search engines by the hand with our guide on Controlling Crawling & Indexing!





