
Use Canonical URL to Resolve Duplicate Content Issues
The link element rel="canonical", often called canonical URL, is a powerful tool to combat duplicate content problems when multiple variants of (more or less) the same page exist.
In essence, it allows you to specify which page variant is the canonical one: the variant that you want to have show up in search engines.
Keep the following best practices in mind when implementing canonical URLs:
- Use absolute URLs, including the domain and protocol.
- Define only one canonical URL per page.
- Define the canonical URL in the page's <head>-section or HTTP header.
- Point to an indexable page.
What is a canonical URL?
Link element rel="canonical", often called canonical URLURL
The term URL is an acronym for the designation "Uniform Resource Locator".
Learn more, is an HTML element which helps prevent duplicate contentDuplicate Content
Duplicate content refers to several websites with the same or very similar content.
Learn more by informing search engines to prefer one document over other identical or similar documents. When pagePage
See Websites
Learn more A has a canonical link element referencing page B, you say that page A has been canonicalized.
Canonicalization is the process in which a preferred version of a page is selected over multiple other versions.
Synonyms for canonical URL
Although their meaning is not the same, the following terms are often used to refer to the canonical URL: canonical tag, canonical link, rel canonical or rel="canonical". For the sake of ease, when we refer to the canonical HTML element we'll call it canonical URL.
Why do you need a canonical URL?
With the canonical URL you can prevent duplicate content, both internally and externally. Internal duplicate content happens within your website. External duplicate content happens when duplicate or very similar pages on different domains exist.
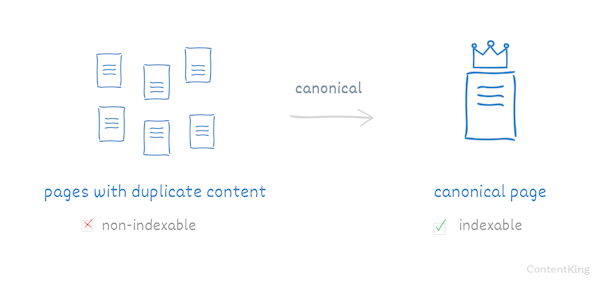
The canonical URL communicates to Google, Bing and Yahoo what pages to show and what pages to hide in the search engineSearch Engine
A search engine is a website through which users can search internet content.
Learn more result pages. Although search engines can choose to ignore the canonical URL, it does give you as a websiteWebsite
A website is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more owner more control over your website's online presence.
What does a canonical URL look like?
Your visitors won't see the canonical URL when visiting your website. A canonical URL can be defined in the page source or in the HTTP header.
Page source
The canonical URL should be located in the <head>-section of the page source. For our homepageHomepage
A homepage is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more, the canonical URL looks as follows:
<head>
<link rel="canonical" href="https://www.contentkingapp.com/" />
</head>HTTP Header
Defining the canonical URL in the HTTP header is often used when you need to set a canonical URL on a non-HTML document, such as a PDF.
In the HTTP header this looks as follows:
HTTP/1.1 200 OK
Server: nginx
Date: Thu, 28 Apr 2016 11:54:25 GMT
Content-Type: application/pdf
Content-Length: 23629
Last-Modified: Fri, 29 Apr 2016 17:47:17 GMT
Link: <http://www.example.com/downloads/whitepaper.pdf>; rel="canonical"Possible scenario's in which you'd need to use the HTTP header to define the canonical URL for a non-HTML document is when content is offered both as a regular page (HTML document) and as a PDF (non-HTML document).
Please note: currently only Google supports defining the canonical URL using the HTTP header. For images, Google does not support a canonical defined through the HTTP header.
When to use a canonical URL?
There's no conceivable scenario in which it's a bad idea to include a canonical URL. Google, Bing and Yahoo heavily rely on the canonical URL to understand what pages to show and hide in search engine result pages. The canonical URL can either reference itself, or reference another page.
Canonical URL referencing itself
If there's only one version of a page, make sure the canonical URL is self-referencing.
This basically tells search engines: "I'm the only version of this page, and only I should be indexed.".
Canonical URL referencing another page
If there are multiple versions of a page, make sure the canonical URL is referencing the page you prefer to be indexed by search engines.
Common cases in which canonical URLs fix duplicate content issues are:
- When query parameters are used in the URL.
- When pages are slightly different, commonly referred to as near duplicates.
- When intentionally multiple versions of a page were created.
Query parameters in URL
Depending on the URL structure of a website, URLs sometimes contain query parameters. Query parameters in URLs are used to request certain content from.
Take for example:
www.example.com/shoes/nike?lang=uk&id=101
- The variable
lang=ukindicates that the language for the requested page is English (UK). - The variable
id=101indicates that page number 101 should be requested. - In between the variables there a
&character which indicates that you want you want the English (UK) version of page 101.
While query parameters are handy, URLs containing query parameters are hard to read and it's easy to create duplicate content. The URL www.example.com/shoes/nike?id=101&lang=uk requests the exact same page as www.example.com/shoes/nike?lang=uk&id=101, but the pages have a different URL. This form of duplicate content can easily be fixed with a canonical URL.
Slightly different pages (near duplicates)
When pages are only slightly different, we often call them 'near duplicate pages' or 'near duplicates'. A good example of near duplicate pages are e-commerce websites that sell shoes. Imagine you have have a Nike Air Max shoe size 38 which is available in red, blue and black. Upon selecting a different color the URL changes, but 99% of the page content stays the same.
- General Nike Air Max size 38:
www.example.com/shoes/nike/men-38/ - General Nike Air Max size 38 in red:
www.example.com/shoes/nike/men-38-red/ - General Nike Air Max size 38 in blue:
www.example.com/shoes/nike/men-38-blue/ - General Nike Air Max size 38 in black:
www.example.com/shoes/nike/men-38-black/
Since the content on these four pages is very similar, it makes sense to have a canonical URL from www.example.com/shoes/nike/men-38-red/, www.example.com/shoes/nike/men-38-blue/ and www.example.com/shoes/nike/men-38-black/ pointing to www.example.com/shoes/nike/men-38/.
Intentionally created multiple versions of a page
There can be many reasons for intentionally creating multiple versions of a page. To give two examples:
- Personalized landing pages for campaigns
- Running conversionConversion
Conversions are processes in online marketing that lead to a defined conclusion.
Learn more rate optimization tests where you test three versions of the same page, which essentially have the same content.
When there are multiple versions of a page, make sure to point the canonical URL to the preferred version which you want to have indexed. When a canonical URL references another URL, this tells search engines:
"There are multiple versions of my page which are either identical or very similar. To make sure your indexIndex
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine’s index, users will not be able to find it.
Learn more is nice and clean, make sure to index the page I'm referencing".
Separate desktop and mobile pages
If you've got separate desktop and mobile pages you should use the canonical URL and the alternate URL to communicate the relation between these pages to search engines.
At the moment Google is the only search engine that supports this specific implementation.
Let's talk about the implementation:
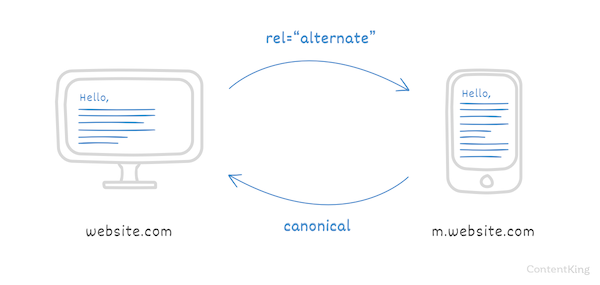
Desktop
On the desktop version of the page the canonical URL and alternate URL in the <head>-section look as follows:
<head>
<link rel="canonical" href="https://www.example.com/" />
<link rel="alternate" href="https://m.example.com/" />
</head>Mobile
On the mobile version of the page the canonical URL in the <head>-section looks as follows:
<head>
<link rel="canonical" href="https://www.example.com/" />
</head>This way search engines show the mobile version of the page for mobile devices, and the desktop version of the page for desktop devices.
Cross-domain canonical
The canonical URL can be used to prevent duplicate content in cases where the duplicate content issues go beyond a single website. When content is published on several pages, on several domains the cross-domain canonical URL can be used to signal to search engines which version of the page should be indexed.
Consolidating unnecessary pages with redirects
When it's not necessary for multiple versions of a page to exist, it's best to redirect the redundant pages to the preferred version. Examples in which a redirect is a much better way to deal with multiple versions of pages:
- A page is available through the HTTP and HTTPS protocols.
- A page is available through multiple domains (
www.example1.com,www.example2.com,www.example3.com) or subdomains (www.example.com,www2.example.com,www3.example.com) and this doesn't serve a purpose.
Please note that, if you're using redirects in the examples above it's recommended to still also use the canonical URL. If your redirects cease to work, you still have your canonical URL in place to prevent indexing issues.
What are best practices around canonical URLs?
The canonical URL is a very powerful tool in a webmaster's toolbox. It's vital to stick to the best practices below when working with canonical URLs in order to prevent indexing issues:
- Use absolute URLs - there can be no doubt about the page a search engine should index. Use the full URL, including protocol (HTTP or HTTPS), subdomain and domain.
- One canonical URL per page - there should always be only one canonical URL per page.
- Placement in <head>-section or HTTP header- the canonical URL should always be placed in the
<head>-section or in the HTTP header - Point to an indexable page - the canonical URL should be pointing to an indexable page.
- Only include the preferred version of a page in the XML sitemap.
Use absolute URLs
We should only use absolute URLs as canonical URLs. Take for example:
<link rel="canonical" href="https://www.example.com/services/repairs/">With this URL as a canonical URL, there is no doubt about the exact location of the URL.
Now compare the canonical URL above to the ambiguous one below:
<link rel="canonical" href="repairs/">Some webservers are by default incorrectly configured, making each page on your website accessible through all domains and subdomains. This causes a tremendous amount of duplicate content, which you should avoid at all times.
Having absolute URLs as canonical URLs prevent these kind of duplicate content issues from happening.
One canonical URL per page
There should always be only one canonical URL per page. If more than one canonical URL is defined, search engines may get confused. Google has stated that they'll just choose one of the canonical URL and ignore the others when they encounter multiple canonical URLs on one page. Although we are not sure how Bing and Yahoo handle multiple canonical URLs per page, they do recommend using only one canonical URL per page.
Placement in <head>-section
The canonical URL should always be placed in the <head>-section of your page. If the canonical URL is not placed in the <head>-section, search engines will not be able to find it and process it. In turn this can lead to leading duplicate content issues.
Reference an indexable page
The canonical URL should always reference an indexable page. Search engines may get confused when the canonical URL references a page which is 301 redirected, or is canonicalized itself.
Include only preferred version in XML sitemap
All pages included in your XML sitemap should be indexable by search engines. Therefore it's important that, in case you have multiple versions of a page, you only include the preferred version of a page in your XML sitemap.
What are the limitations of canonical URL?
While canonical URLs are a great tool in a webmaster's toolbox, it also has its limitations.
Consolidating link authority only partially
Let's consider an example: page A has some really powerful backlinksBacklinks
Backlinks are links from outside domains that point to pages on your domain; essentially linking back from their domain to yours.
Learn more. Page A references page B as its canonical. Search engines will most likely index page B and leave page A out of their index.
Each link passes on some authority, called link authority. The link authority that is passed on to page A through the powerful backlinks, is only partially passed on to page B. We say only partially because this is a grey area about which search engines aren't very clear. There is no research showing that a canonical URL passes all link authority. On top of that, the canonical URL has been introduced to communicate to search engines what pages to show and what pages to hide. Therefore, our stance on this topic is: a canonical URL does not fully pass on link authority.
Google's Matt Cutts has said that "there's really not a lot of difference between them [301 redirect and canonical URL]".
If you want to pass on as much link authority as possible on, we advise you to use a 301 redirect.
Canonical URLs do not prevent crawl optimization issues
Canonical URLs are meant to fix duplicate content issues. A canonical URL tells search engines what pages to index, but does not tell search engines what pages to crawl. This is an important distinction to make.
When search engines are not spending their time crawling useful and important pages then we say there are crawl optimization issues. There are numerous reasons why search engines are not crawling useful and important pages. Search engines may get caught in infinite redirect loops, spend a lot of time crawling pages which you don't want to have indexed in the first place or keep hitting dead ends in your website (pages with no links to other pages). That's a waste, especially since search engines have a so called 'crawl budget' (the allotted time for crawling a website) for each website. The robots.txt can be used to prevent crawl optimization issues.
Frequently asked questions about canonical URLs
1. Are canonical URLs passing any link authority?
We suspect that some link authority is passed on when canonicalizing URLs.
As written in section "Consolidating link authority only partially", we can't say for certain whether or not a canonical URL passes on link authority. What we do know is that a canonical URL isn't meant to pass on link authority, that's what 301 redirects are for.
2. Can I force search engines to use my canonical URL?
No, the canonical URL is an advice rather than a directive for search engines.
3. Is a canonical URL better than a 301 redirect?
A canonical URL and a 301 redirect are two entirely different means to an end.
A canonical URL is used when all versions of the page should be accessible to visitors but only one of them should be indexed by search engines.
A 301 redirect forwards both visitors and search engines from one URL to another URL. A redirected URL is not accessible for visitors or search engines.
4. Can I mess up my website with canonical URLs?
When incorrectly used, canonical URLs can cause major issues for the indexing of your website.
For example, imagine that for some reason all of your pages have a canonical to the homepage. Since the canonical URL is such as strong signal for search engines, they will most likely process it and de-index the canonicalized pages.
Even though you have to be careful with canonical URLs, we strongly advise you to use them in order to communicate to search engines what pages to index, and what pages to hide.
5. Do all search engines support the canonical URL?
We know that Google, Bing and Yahoo support the canonical URL.
Yandex and Baidu seem to support the canonical URL as well. For DuckDuckGo it's unclear.
6. How do search engines deal with multiple canonical URLs on one page?
Google has stated that they will ignore the canonical URL elements altogether if there are multiple canonical URLs on one page.
It's unclear how other search engines deal with this, although we strongly advise to use only one canonical URL per page.
7. Does a canonical URL prevent pages from being crawled?
No, it does not. Search engines will still crawl your pages, regardless of whether or not you've set a canonical URL pointing to a different URL. A canonical URL is merely a strong signal for search engines regarding the preferred page that should be showing up in search engine result pages. Also see Canonical URLs do not prevent crawl optimization issues.
8. Should I use canonical URLs for paginated pages?
Generally it's recommended not to use the canonical URL for paginated pages, since paginated pages often don't show the same content. Instead, it's recommended to use rel="next" and rel="prev" link elements. That's a better way to explain to search engines that the paginated pages are in fact a series of pages who follow a logical sequence.
You can use a canonical URL for paginated page, but only if you have a View All page which loads fast. In that case you reference the View All page on all the paginated pages as the canonical URL.




