
Robots.txt for SEO: The Ultimate Guide
A robots.txt file contains directives for search engines. You can use it to prevent search engines from crawling specific parts of your website and to give search engines helpful tips on how they can best crawl your website. The robots.txt file plays a big role in SEO.
When implementing robots.txt, keep the following best practices in mind:
- Be careful when making changes to your robots.txt: this file has the potential to make big parts of your website inaccessible for search engines.
- The robots.txt file should reside in the root of your website (e.g. http://www.example.com/robots.txt).
- The robots.txt file is only valid for the full domain it resides on, including the protocol (http or https).
- Different search engines interpret directives differently. By default, the first matching directive always wins. But, with Google and Bing, specificity wins.
- Avoid using the crawl-delay directive for search engines as much as possible.
What is a robots.txt file?
A robots.txtRobots.txt
Robots.txt file is a text file that can be saved to a website’s server.
Learn more file tells search engines what your website's rules of engagement are. A big part of doing SEO is about sending the right signals to search engines, and the robots.txt is one of the ways to communicate your crawling preferences to search engines.
In 2019, we've seen quite some developments around the robots.txt standard: Google proposed an extension to the Robots Exclusion Protocol and open-sourced its robots.txt parser .
TL;DR
- Google's robots.txt interpreter is quite flexible and surprisingly forgiving.
- In case of confusion directives, Google errs on the safe sides and assumes sections should be restricted rather than unrestricted.
Search engines regularly check a website's robots.txt file to see if there are any instructions for crawling the websiteWebsite
A website is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more. We call these instructions directives.
If there's no robots.txt file present or if there are no applicable directives, search engines will crawl the entire website.
Although all major search engines respect the robots.txt file, search engines may choose to ignore (parts of) your robots.txt file. While directives in the robots.txt file are a strong signal to search engines, it's important to remember the robots.txt file is a set of optional directives to search engines rather than a mandate.

The robots.txt is the most sensitive file in the SEO universe. A single character can break a whole site.
Terminology around robots.txt file
The robots.txt file is the implementation of the robots exclusion standard, or also called the robots exclusion protocol.
Why should you care about robots.txt?
The robots.txt plays an essential role from a SEO point of view. It tells search engines how they can best crawl your website.
Using the robots.txt file you can prevent search engines from accessing certain parts of your website, prevent duplicate content and give search engines helpful tips on how they can crawl your website more efficiently.
Be careful when making changes to your robots.txt though: this file has the potential to make big parts of your website inaccessible for search engines.

Robots.txt is often over used to reduce duplicate content, thereby killing internal linking so be really careful with it. My advice is to only ever use it for files or pages that search engines should never see, or can significantly impact crawling by being allowed into. Common examples: log-in areas that generate many different urls, test areas or where multiple facetted navigation can exist. And make sure to monitor your robots.txt file for any issues or changes.
![Paul Shapiro, Head of Technical SEO & SEO Product Management, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/fd312eea58cfe5f254dd24cc22873cef2f57ffbb-450x450.jpg?dpr=1&fit=min&h=100&q=95&w=100)
The mass majority of issues I see with robots.txt files fall into three buckets:
- The mishandling of wildcards. It's fairly common to see parts of the site blocked off that were intended to be blocked off. Sometimes, if you aren't careful, directives can also conflict with one another.
- Someone, such as a developer, has made a change out of the blue (often when pushing new code) and has inadvertently altered the robots.txt without your knowledge.
- The inclusion of directives that don't belong in a robots.txt file. Robots.txt is web standard, and is somewhat limited. I oftentimes see developers making directives up that simply won't work (at least for the mass majority of crawlers). Sometimes that's harmless, sometimes not so much.
Example
Let's look at an example to illustrate this:
You're running an eCommerce website and visitors can use a filter to quickly search through your products. This filter generates pages which basically show the same content as other pages do. This works great for users, but confuses search engines because it creates duplicate content.
You don't want search engines to indexIndex
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine’s index, users will not be able to find it.
Learn more these filtered pages and waste their valuable time on these URLs with filtered content. Therefor, you should set up Disallow rules so search engines don't access these filtered product pages.
Preventing duplicate contentDuplicate Content
Duplicate content refers to several websites with the same or very similar content.
Learn more can also be done using the canonical URL or the meta robots tag, however these don't address letting search engines only crawl pages that matter.
Using a canonical URLURL
The term URL is an acronym for the designation "Uniform Resource Locator".
Learn more or meta robots tag will not prevent search engines from crawling these pages. It will only prevent search engines from showing these pages in the search results. Since search engines have limited time to crawl a website, this time should be spend on pages that you want to appear in search engines.

It's a very simple tool, but a robots.txt file can cause a lot of problems if it's not configured correctly, particularly for larger websites. It's very easy to make mistakes such as blocking an entire site after a new design or CMS is rolled out, or not blocking sections of a site that should be private. For larger websites, ensuring Google crawl efficiently is very important and a well structured robots.txt file is an essential tool in that process.
What does a robots.txt file look like?
An example of what a simple robots.txt file for a WordPress website may look like:
User-agent: *
Disallow: /wp-admin/Let's explain the anatomy of a robots.txt file based on the example above:
- User-agent: the
user-agentindicates for which search engines the directives that follow are meant. *: this indicates that the directives are meant for all search engines.Disallow: this is a directive indicating what content is not accessible to theuser-agent./wp-admin/: this is thepathwhich is inaccessible for theuser-agent.
In summary: this robots.txt file tells all search engines to stay out of the /wp-admin/ directory.
Let's analyze the different components of robots.txt files in more detail:
User-agent in robots.txt
Each search engineSearch Engine
A search engine is a website through which users can search internet content.
Learn more should identify themself with a user-agent. Google's robots identify as Googlebot for example, Yahoo's robots as Slurp and Bing's robot as BingBot and so on.
The user-agent record defines the start of a group of directives. All directives in between the first user-agent and the next user-agent record are treated as directives for the first user-agent.
Directives can apply to specific user-agents, but they can also be applicable to all user-agents. In that case, a wildcard is used: User-agent: *.
Disallow directive in robots.txt
You can tell search engines not to access certain files, pages or sections of your website. This is done using the Disallow directive. The Disallow directive is followed by the path that should not be accessed. If no path is defined, the directive is ignored.
Example
User-agent: *
Disallow: /wp-admin/In this example all search engines are told not to access the /wp-admin/ directory.
Allow directive in robots.txt
The Allow directive is used to counteract a Disallow directive. The Allow directive is supported by Google and Bing. Using the Allow and Disallow directives together you can tell search engines they can access a specific file or pagePage
See Websites
Learn more within a directory that's otherwise disallowed. The Allow directive is followed by the path that can be accessed. If no path is defined, the directive is ignored.
Example
User-agent: *
Allow: /media/terms-and-conditions.pdf
Disallow: /media/In the example above all search engines are not allowed to access the /media/ directory, except for the file /media/terms-and-conditions.pdf.
Important: when using Allow and Disallow directives together, be sure not to use wildcards since this may lead to conflicting directives.
Example of conflicting directives
User-agent: *
Allow: /directory
Disallow: *.htmlSearch engines will not know what to do with the URL http://www.domain.com/directory.html. It's unclear to them whether they're allowed to access. When directives aren't clear to Google, they will go with the least restrictive directive, which in this case means that they would in fact access http://www.domain.com/directory.html.

Disallow rules in a site's robots.txt file are incredibly powerful, so should be handled with care. For some sites, preventing search engines from crawling specific URL patterns is crucial to enable the right pages to be crawled and indexed - but improper use of disallow rules can severely damage a site's SEO.
A separate line for each directive
Each directive should be on a separate line, otherwise search engines may get confused when parsing the robots.txt file.
Example of incorrect robots.txt file
Prevent a robots.txt file like this:
User-agent: * Disallow: /directory-1/ Disallow: /directory-2/ Disallow: /directory-3/![David Iwanow, Head of Search, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/5f4996305d653e2847aefbe94b078a20c02ab41c-200x200.jpg?dpr=1&fit=min&h=100&q=95&w=100)
Robots.txt is one of the features I most commonly see implemented incorrectly so it's not blocking what they wanted to block or it's blocking more than they expected and has a negative impact on their website. Robots.txt is a very powerful tool but too often it's incorrectly setup.
Using wildcard *
Not only can the wildcard be used for defining the user-agent, it can also be used to match URLs. The wildcard is supported by Google, Bing, Yahoo and Ask.
Example
User-agent: *
Disallow: *?In the example above all search engines aren't allowed access to URLs which include a question mark (?).

Developers or site-owners often seem to think they can utilize all manner of regular expression in a robots.txt file whereas only a very limited amount of pattern matching is actually valid - for example wildcards (
*). There seems to be a confusion between.htaccessfiles and robots.txt files from time to time.
Using end of URL $
To indicate the end of a URL, you can use the dollar sign ($) at the end of the path.
Example
User-agent: *
Disallow: *.php$In the example above search engines aren't allowed to access all URLs which end with .php. URLs with parameters, e.g. https://example.com/page.php?lang=en would not be disallowed, as the URL doesn't end after .php.
Add sitemap to robots.txt
Even though the robots.txt file was invented to tell search engines what pages not to crawl, the robots.txt file can also be used to point search engines to the XML sitemap. This is supported by Google, Bing, Yahoo and Ask.
The XML sitemap should be referenced as an absolute URL. The URL does not have to be on the same host as the robots.txt file.
Referencing the XML sitemap in the robots.txt file is one of the best practices we advise you to always do, even though you may have already submitted your XML sitemap in Google Search ConsoleGoogle Search Console
The Google Search Console is a free web analysis tool offered by Google.
Learn more or Bing Webmaster Tools. Remember, there are more search engines out there.
Please note that it's possible to reference multiple XML sitemaps in a robots.txt file.
Examples
Multiple XML sitemaps defined in a robots.txt file:
User-agent: *
Disallow: /wp-admin/
Sitemap: https://www.example.com/sitemap1.xml
Sitemap: https://www.example.com/sitemap2.xmlThe example above tells all search engines not to access the directory /wp-admin/ and that there are two XML sitemaps which can be found at https://www.example.com/sitemap1.xml and https://www.example.com/sitemap2.xml.
A single XML sitemap defined in a robots.txt file:
User-agent: *
Disallow: /wp-admin/
Sitemap: https://www.example.com/sitemap_index.xmlThe example above tells all search engines not to access the directory /wp-admin/ and that the XML sitemap can be found at https://www.example.com/sitemap_index.xml.
Comments
Comments are preceded by a # and can either be placed at the start of a line or after a directive on the same line. Everything after the # will be ignored. These comments are meant for humans only.
Example 1
# Don't allow access to the /wp-admin/ directory for all robots.
User-agent: *
Disallow: /wp-admin/Example 2
User-agent: * #Applies to all robots
Disallow: /wp-admin/ # Don't allow access to the /wp-admin/ directory.The examples above communicate the same message.
Crawl-delay in robots.txt
The Crawl-delay directive is an unofficial directive used to prevent overloading servers with too many requests. If search engines are able to overload a server, adding Crawl-delay to your robots.txt file is only a temporary fix. The fact of the matter is, your website is running on a poor hosting environment and/or your website is incorrectly configured, and you should fix that as soon as possible.
The way search engines handle the Crawl-delay differs. Below we explain how major search engines handle it.
Crawl-delay and Google
Google's crawler, Googlebot, does not support the Crawl-delay directive, so don't bother with defining a Google crawl-delay.
However, Google does support defining a crawl rate (or "request rate" if you will) in Google Search Console.
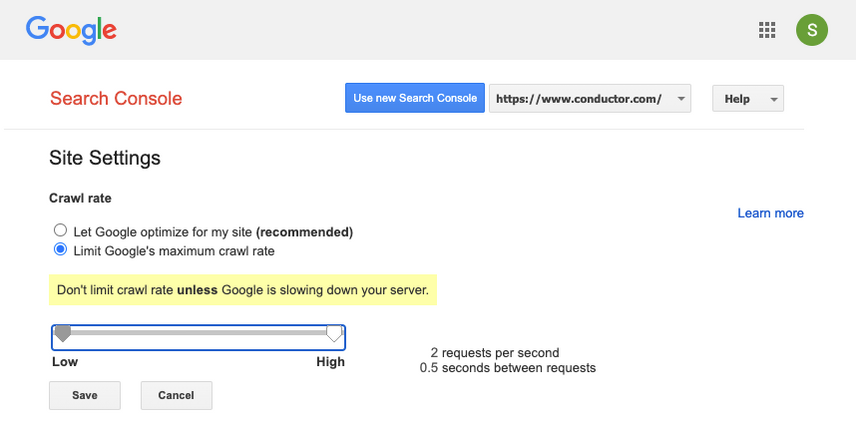
Setting crawl rate in GSC
- Log onto the old Google Search Console .
- Choose the website you want to define the crawl rate for.
- There's only one setting you can tweak:
Crawl rate, with a slider where you can set the preferred crawl rate. By default the crawl rate is set to "Let Google optimize for my site (recommended)".
This is what that looks like in Google Search Console:
Crawl-delay and Bing, Yahoo and Yandex
Bing, Yahoo and Yandex all support the Crawl-delay directive to throttle crawling of a website. Their interpretation of the crawl-delay is slightly different though, so be sure to check their documentation:
The Crawl-delay directive should be placed right after the Disallow or Allow directives.
Example:
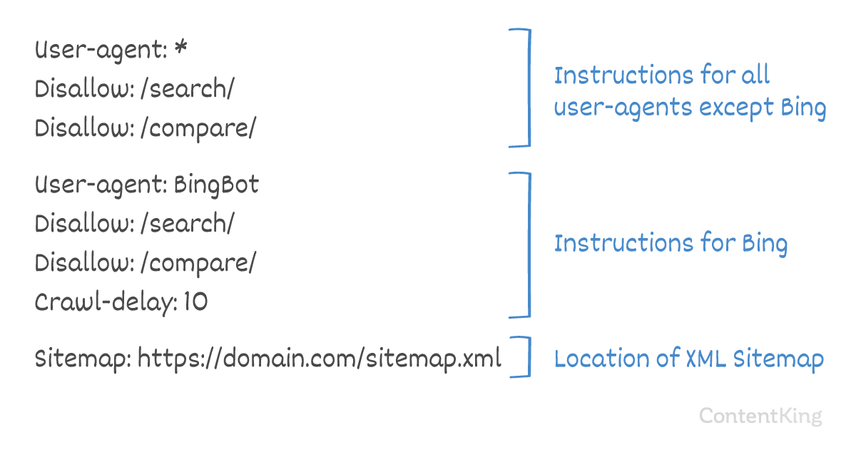
User-agent: BingBot
Disallow: /private/
Crawl-delay: 10Crawl-delay and Baidu
Baidu does not support the crawl-delay directive, however it's possible to register a Baidu Webmaster Tools account in which you can control the crawl frequency, similar to Google Search Console.
When to use a robots.txt file?
We recommend to always use a robots.txt file. There's absolutely no harm in having one, and it's a great place to hand search engines directives on how they can best crawl your website.

The robots.txt can be useful to keep certain areas or documents on your site from being crawled and indexed. Examples are for instance the staging site or PDFs. Plan carefully what needs to be indexed by search engines and be mindful that content that's been made inaccessible through robots.txt may still be found by search engine crawlers if it's linked to from other areas of the website.
Robots.txt best practices
The robots.txt best practices are categorized as follows:
- Location and filename
- Order of precedence
- Only one group of directives per robot
- Be as specific as possible
- Directives for all robots while also including directives for a specific robot
- Robots.txt file for each (sub)domain.
- Conflicting guidelines: robots.txt vs. Google Search Console
- Monitor your robots.txt file
- Don't use noindex in your robots.txt
- Prevent UTF-8 BOM in robots.txt file
Location and filename
The robots.txt file should always be placed in the root of a website (in the top-level directory of the host) and carry the filename robots.txt, for example: https://www.example.com/robots.txt. Note that the URL for the robots.txt file is, like any other URL, case-sensitive.
If the robots.txt file cannot be found in the default location, search engines will assume there are no directives and crawl away on your website.
Order of precedence
It's important to note that search engines handle robots.txt files differently. By default, the first matching directive always wins.
However, with Google and Bing specificity wins. For example: an Allow directive wins over a Disallow directive if its character length is longer.
Example
User-agent: *
Allow: /about/company/
Disallow: /about/In the example above all search engines, including Google and Bing are not allowed to access the /about/ directory, except for the sub-directory /about/company/.
Example
User-agent: *
Disallow: /about/
Allow: /about/company/In the example above, all search engines except for Google and Bing, aren't allowed access to /about/ directory. That includes the directory /about/company/.
Google and Bing are allowed access, because the Allow directive is longer than the Disallow directive.
Only one group of directives per robot
You can only define one group of directives per search engine. Having multiple groups of directives for one search engine confuses them.
Be as specific as possible
The Disallow directive triggers on partial matches as well. Be as specific as possible when defining the Disallow directive to prevent unintentionally disallowing access to files.
Example:
User-agent: *
Disallow: /directoryThe example above doesn't allow search engines access to:
/directory/directory//directory-name-1/directory-name.html/directory-name.php/directory-name.pdf
Directives for all robots while also including directives for a specific robot
For a robot only one group of directives is valid. In case directives meant for all robots are followed with directives for a specific robot, only these specific directives will be taken into considering. For the specific robot to also follow the directives for all robots, you need to repeat these directives for the specific robot.
Let's look at an example which will make this clear:
Example
User-agent: *
Disallow: /secret/
Disallow: /test/
Disallow: /not-launched-yet/
User-agent: googlebot
Disallow: /not-launched-yet/In the example above all search engines except for Google are not allowed to access /secret/, /test/ and /not-launched-yet/. Google only isn't allowed access to /not-launched-yet/, but is allowed access to /secret/ and /test/.
If you don't want googlebot to access /secret/ and /not-launched-yet/ then you need to repeat these directives for googlebot specifically:
User-agent: *
Disallow: /secret/
Disallow: /test/
Disallow: /not-launched-yet/
User-agent: googlebot
Disallow: /secret/
Disallow: /not-launched-yet/Please note that your robots.txt file is publicly available. Disallowing website sections in there can be used as an attack vector by people with malicious intent.

Robots.txt can be dangerous. You're not only telling search engines where you don't want them to look, you're telling people where you hide your dirty secrets.
Robots.txt file for each (sub)domain
Robots.txt directives only apply to the (sub)domain the file is hosted on.
Examples
http://example.com/robots.txt is valid for http://example.com, but not for http://www.example.com or https://example.com.
It's a best practice to only have one robots.txt file available on your (sub)domain.
If you have multiple robots.txt files available, be sure to either make sure they return a HTTP status 404, or to 301 redirect them to the canonical robots.txt file.
Conflicting guidelines: robots.txt vs. Google Search Console
In case your robots.txt file is conflicting with settings defined in Google Search Console, Google often chooses to use the settings defined in Google Search Console over the directives defined in the robots.txt file.
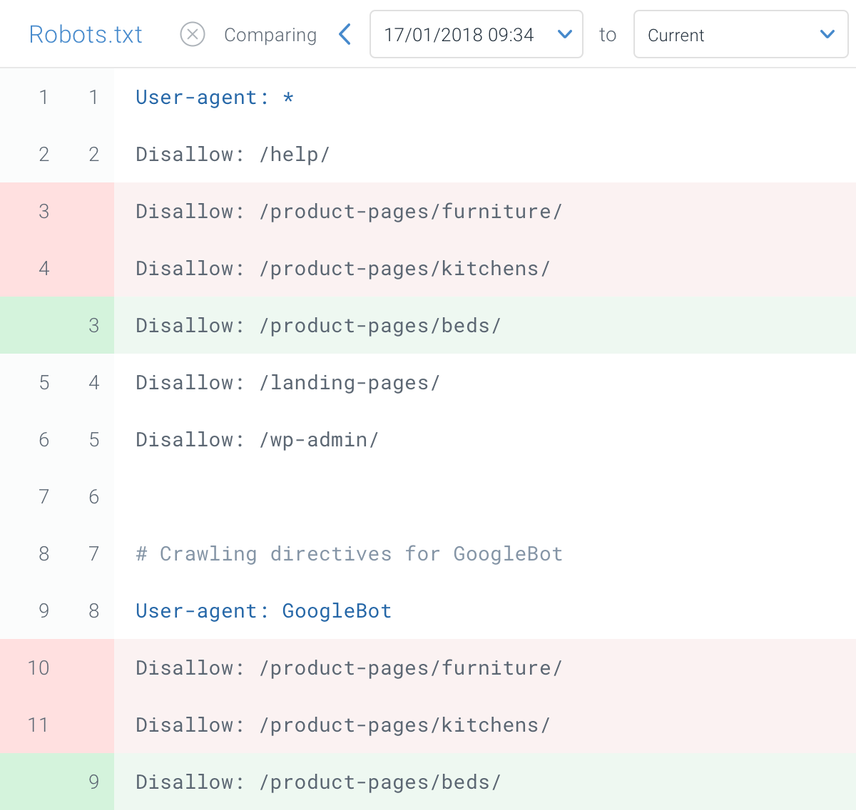
Monitor your robots.txt file
It's important to monitor your robots.txt file for changes. At ContentKing, we see lots of issues where incorrect directives and sudden changes to the robots.txt file cause major SEO issues.
This holds true especially when launching new features or a new website that has been prepared on a test environment, as these often contain the following robots.txt file:
User-agent: *
Disallow: /We built robots.txt change tracking and alerting for this reason.
Don't use noindex in your robots.txt
For years, Google was already openly recommending against using the unofficial noindex directive . As of September 1, 2019 however, Google stopped supporting it entirely .
The unofficial noindex directive never worked in Bing, as confirmed by Frédéric Dubut in this tweet :
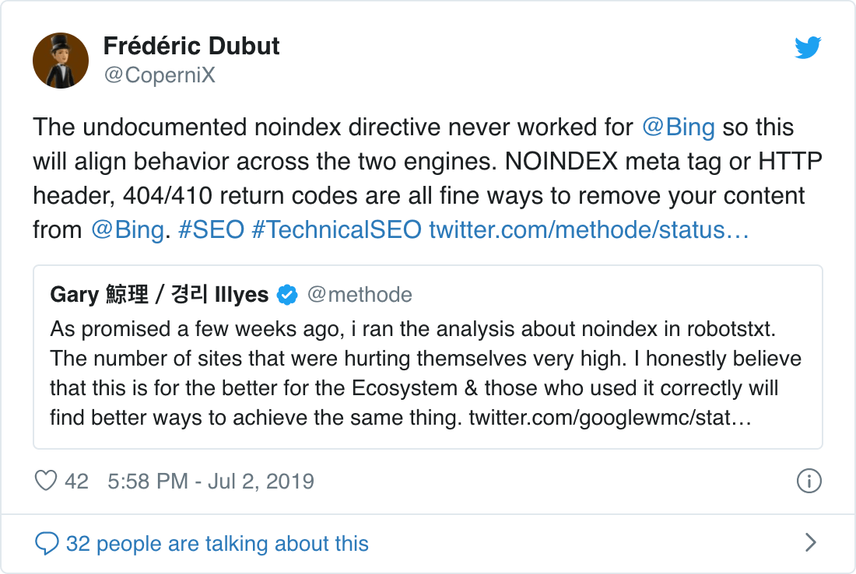
The best way to signal to search engines that pages should not be indexed is using the meta robots tag or X-Robots-Tag.
Prevent UTF-8 BOM in robots.txt file
BOM stands for byte order mark, an invisible character at the beginning of a file used to indicate Unicode encoding of a text file.
While Google states they ignore the optional Unicode byte order mark at the beginning of the robots.txt file, we recommend preventing the "UTF-8 BOM" because we've seen it cause issues with the interpretation of the robots.txt file by search engines.
Even though Google says they can deal with it, here are two reasons to prevent the UTF-8 BOM:
- You don't want there to be any ambiguity about your preferences around crawling to search engines.
- There are other search engines out there, which may not be as forgiving as Google claims to be.
Robots.txt examples
In this chapter we'll cover a wide range of robots.txt file examples:
- Allow all robots access to everything
- Disallow all robots access to everything
- All Google bots don't have access
- All Google bots, except for Googlebot news don't have access
- Googlebot and Slurp don't have any access
- All robots don't have access to two directories
- All robots don't have access to one specific file
- Googlebot doesn't have access to /admin/ and Slurp doesn't have access to /private/
- Robots.txt file for WordPress
- Robots.txt file for Magento
Allow all robots access to everything
There's multiple ways to tell search engines they can access all files:
User-agent: *
Disallow:Or having an empty robots.txt file or not having a robots.txt at all.
Disallow all robots access to everything
The example robots.txt below tells all search engines not to access the entire site:
User-agent: *
Disallow: /Please note that just ONE extra character can make all the difference.
All Google bots don't have access
User-agent: googlebot
Disallow: /Please note that when disallowing Googlebot, this goes for all Googlebots. That includes Google robots which are searching for instance for news (googlebot-news) and images (googlebot-images).
All Google bots, except for Googlebot news don't have access
User-agent: googlebot
Disallow: /
User-agent: googlebot-news
Disallow:Googlebot and Slurp don't have any access
User-agent: Slurp
User-agent: googlebot
Disallow: /All robots don't have access to two directories
User-agent: *
Disallow: /admin/
Disallow: /private/All robots don't have access to one specific file
User-agent: *
Disallow: /directory/some-pdf.pdfGooglebot doesn't have access to /admin/ and Slurp doesn't have access to /private/
User-agent: googlebot
Disallow: /admin/
User-agent: Slurp
Disallow: /private/Robots.txt file for WordPress
The robots.txt file below is specifically optimized for WordPress, assuming:
- You don't want to have your admin section to be crawled.
- You don't want to have your internal search resultSearch Result
Search results refer to the list created by search engines in response to a query.
Learn more pages crawled. - You don't want to have your tag and author pages crawled.
- You don't want your 404 page to be crawled.
User-agent: *
Disallow: /wp-admin/ #block access to admin section
Disallow: /wp-login.php #block access to admin section
Disallow: /search/ #block access to internal search result pages
Disallow: *?s=* #block access to internal search result pages
Disallow: *?p=* #block access to pages for which permalinks fails
Disallow: *&p=* #block access to pages for which permalinks fails
Disallow: *&preview=* #block access to preview pages
Disallow: /tag/ #block access to tag pages
Disallow: /author/ #block access to author pages
Disallow: /404-error/ #block access to 404 page
Sitemap: https://www.example.com/sitemap_index.xmlPlease note that this robots.txt file will work in most cases, but you should always adjust it and test it to make sure it applies to your exact situation.
Robots.txt file for Magento
The robots.txt file below is specifically optimized for Magento, and will make internal search results, login pages, session identifiers and filtered result sets that contain price, color, material and size criteria inaccessible to crawlersCrawlers
A crawler is a program used by search engines to collect data from the internet.
Learn more.
User-agent: *
Disallow: /catalogsearch/
Disallow: /search/
Disallow: /customer/account/login/
Disallow: /*?SID=
Disallow: /*?PHPSESSID=
Disallow: /*?price=
Disallow: /*&price=
Disallow: /*?color=
Disallow: /*&color=
Disallow: /*?material=
Disallow: /*&material=
Disallow: /*?size=
Disallow: /*&size=
Sitemap: https://www.example.com/sitemap_index.xmlPlease note that this robots.txt file will work for most Magento stores, but you should always adjust it and test it to make sure it applies to your exact situation.
I'd still always look to block internal search results in robots.txt on any site because these types of search URLs are infinite and endless spaces. There's a lot of potential for Googlebot getting into a crawler trap.
What are the limitations of the robots.txt file?
Robots.txt file contains directives
Even though the robots.txt is well respected by search engines, it's still a directive and not a mandate.
Pages still appearing in search results
Pages that are inaccessible for search engines due to the robots.txt, but do have links to them can still appear in search results if they are linked from a page that is crawled. An example of what this looks like:

It's possible to remove these URLs from Google using Google Search Console's URL removal tool. Please note that these URLs will only be temporarily "hidden". In order for them to stay out Google's result pages you need to submit a request to hide the URLs every 180 days.

Use robots.txt to block out undesirable and likely harmful affiliate backlinks. Do not use robots.txt in an attempt to prevent content from being indexed by search engines, as this will inevitably fail. Instead apply robots directive
noindexwhen necessary.
Robots.txt file is cached up to 24 hours
Google has indicated that a robots.txt file is generally cached for up to 24 hours. It's important to take this into consideration when you make changes in your robots.txt file.
It's unclear how other search engines deal with caching of robots.txt, but in general it's best to avoid caching your robots.txt file to avoid search engines taking longer than necessary to be able to pick up on changes.
Robots.txt file size
For robots.txt files Google currently supports a file size limit of 500 kibibytes (512 kilobytes). Any content after this maximum file size may be ignored.
It's unclear whether other search engines have a maximum file size for robots.txt files.
Frequently asked questions about robots.txt
What does a robots.txt example look like?
Here's an example of a robots.txt's content: User-agent: * Disallow: . This tell all crawlers they can access everything.
What does Disallow all do in robots.txt?
When you set a robots.txt to "Disallow all", you're essentially telling all crawlers to keep out. No crawlers, including Google, are allowed access to your site. This means they won't be able to crawl, index and rank your site. This will lead to a massive drop in organic traffic.
What does Allow all do in robots.txt?
When you set a robots.txt to "Allow all", you tell every crawler they can access every URL on the site. There are simply no rules of enagement. Please note that this is the equivalent of having an empty robots.txt, or having no robots.txt at all.
How important is the robots.txt for SEO?
In general, the robots.txt file is very important for SEO purposes. For larger websites the robots.txt is essential to give search engines very clear instructions on what content not to access.
- How do I create a robots.txt?
- How do I find my robots.txt file?
- What search engines respect robots.txt?
- Robots.txt example file
- Does a robots.txt disallow instruct search engines to deindex pages?
- Does Google still support the robots.txt noindex directive?
- What does crawl-delay: 10 mean in robots.txt?
- How do I reference my sitemap in robots.txt?
- Robots.txt checker: is your robots.txt set up correctly?
- Should I block SEMrush in my robots.txt?
- How to prevent search engines from indexing WordPress search result pages?




