
JavaScript SEO Best Practices Guide for Beginners
If your website heavily relies on client-side rendered JavaScript, search engines are having a difficult time crawling and indexing it efficiently. In most cases, this means your site won't rank well.
Learn how Google handles JavaScript sites, and what best practices you can apply to make your JavaScript site perform as well as any other site!
What is JavaScript SEO?
JavaScript SEO encompasses everything you need to do to make a JavaScript-reliant websiteWebsite
A website is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more perform well in search engines. Think of it as a specialization within Technical SEO.
Why is it important?
Developers will tell you JavaScript is amazing and rave on about AngularJS, Vue, Backbone, or React. They’re in love with JavaScript because it lets them create highly interactive web pagesWeb Pages
When you enter an internet address (a URL, e.g. https://login.1und1.de/) into a web browser, a webpage will appear.
Learn more that people love.
SEOs will tell you that JavaScript is often horrible for your SEO performance, and they’ll even go as far as saying that JavaScript is job security for them while quickly pulling up charts showing sharp declining organic traffic after a site starts relying on client-side rendering.
Both are right.
At the same time, when developers and SEOs work together productively, they can achieve great results. When they focus on creating the best possible experience for both visitors and search engines, even JavaScript-reliant websites can perform very well in search.
For a JavaScript-reliant website to perform well in search, it’s absolutely vital that search engines be able to fully understand what your pages are about and what your crawling and indexing guidelines are from the initial HTML response.
But, what is JavaScript?
Glad you asked! JavaScript is a programming language for the web that runs locally within your browser. It’s used to make web pages come to life. For instance, it’s used to deliver notifications, personalize websites, automatically pull in content updates, or load new content as you almost reach the bottom of a pagePage
See Websites
Learn more.
Your most visited websites are heavily relying on JavaScript to function!
Twitter, Facebook, Instagram, YouTube, Netflix—they all use JavaScript.
And it’s highly unlikely that your own site doesn’t use JavaScript. It’s everywhere, and it’s not going away. JavaScript adoption will only grow further.
In a 2019 survey, 67.8% of developers said they were using JavaScript. GitHub confirms its popularity—and shows that it has consistently been the most popular programming language for several consecutive years now.

In the final analysis, all the root problems that JavaScript-powered websites have with SEO stems from the fact that it's the wrong tool for the job. JavaScript frameworks are great for building web apps with. However, web apps are not websites. It's this fundamental mismatch between what JS frameworks are for and what websites are for that causes almost all of the friction between search engines and JavaScript sites.
We now have an entire generation of developers who instinctively reach for a JavaScript solution to any problem, yet often those problems are best solved with old-fashioned HTML and CSS. Until we bridge this divide, JavaScript will continue to be a problem for SEO - and vice versa. Not that I mind too much - I make a lot of money from JavaScript websites built by developers who, belatedly, take SEO seriously and realise they lack the fundamental knowledge to do so.
How does JavaScript impact your SEO performance?
Web pages that heavily rely on JavaScript get indexed slowly. Before we can explain why, we first need to touch on how HTTP requests work and how JavaScript affects web pages.
How HTTP requests work
When you navigate to a URLURL
The term URL is an acronym for the designation "Uniform Resource Locator".
Learn more, your browser requests the URL’s content from the server. If the request was successful, the server responds with the HTML document for that URL. This HTML document contains the text, with references to external files such as images, CSS, and JavaScript if these are present. If they are, your browser creates additional, separate requests for these files too.
JavaScript execution comes into play
The next step is for your browser to construct the DOM and start rendering the web page. Part of this process is executing the JavaScript code which modifies the DOM. These can be small modifications (e.g. loading support chat) or big ones (e.g. loading all of the page’s content).
The page appears in your browser, and you can interact with it. But, JavaScript rendering that heavily modifies the DOM can add seconds to the time it takes for the page to become interactive for visitors.
We call these modifications to the DOM client-side rendering ("CSR" for short)—JavaScript rendering that’s done on the client side, in this case your browser. JavaScript rendering can be slow for various reasons, such as for example a lot of content that needs to be pulled in, a lot of additional requests that need to be made, and inefficient code.
A lot of WordPress themes, for example, are horribly bloated with JavaScript because they load lots of—often unnecessary—JavaScript libraries. Google's Lighthouse goes as far as to even propose alternative JavaScript libraries .
![Aleyda Solís, International SEO Consultant & Founder, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/87a1f817c8f42ea11c23fda5f2aef5c31bfc83b5-1271x1271.png?dpr=1&fit=min&h=100&q=95&w=100)
Just in the last few months, I've had 3 clients using JavaScript to not only implement but also change some pages meta data, as well as canonical tags and main navigation elements. These were large websites, with millions of URLs that were also suffering from speed issues with non-trivial rendering times (partially caused by the high usage of JavaScript).
Although in some scenarios non-trivial changes needed to be made within the platforms, it was clear that the way JavaScript was being used here was unnecessary and harming the ability of the site to be fully and consistently crawled and indexed.
Ultimately, this lead to a bad page experience due to the higher loading times, and needed to be addressed. When the changes started to be made, it was really noticeable in the websites crawling, indexing and speed performance.

Over the last few years, JavaScript SEO has become very complicated. It's no longer just about client-side rendering, server-side rendering, or pre-rendering. It is now crucial to understand precisely how and where JavaScript is used within your page’s layout.
In the end, JavaScript comes at a cost. There are more and more components adding up to the overall cost of your website’s code. Starting from the CPU limitations on mobile devices directly affecting your Core Web Vitals to unoptimized JavaScript causing issues with your website’s indexing in search engines through Web Rendering Service’s & Virtual Clock’s bottlenecks.
Long story short - JavaScript is fantastic. Just make sure that you have a JavaScript SEO expert on your side when designing your flashy new web experience.
What is the DOM?
Above we mentioned the “DOM”. The DOM is an object-oriented representation of a web page, which can be modified using a programming language such as JavaScript.
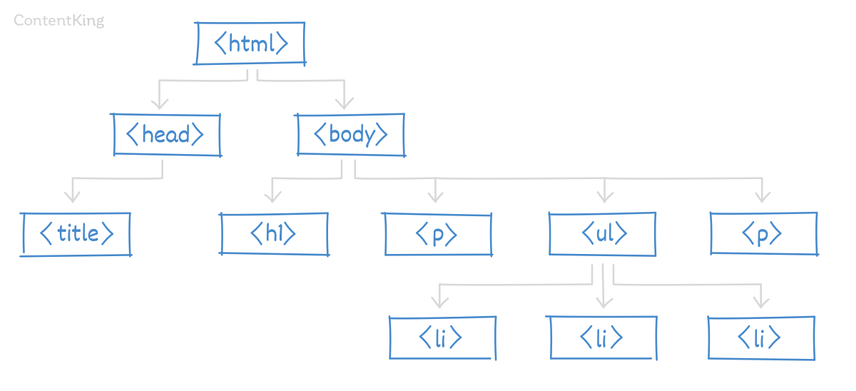
DOM stands for Document Object Model:
- Document: This is the web page.
- Object: Every element on the web page (e.g.
<head></head>,<body></body>,<title></title>,<h1></h1>and<p></p>). - Model: Describes the hierarchy within the document (e.g.
<title></title>goes into the<head></head>).
The issues this presents
If it took your browser several seconds to fully render the web page, and the page source didn’t contain much body content, then how will search engines figure out what this page is about?
They’ll need to render the page, similar to what your browser just did, but without having to display it on a screen. Search engines use a so-called “headless browser.”
Compared to just downloading HTML, rendering JavaScript is super resource-heavy (think 100 times more expensive). That’s why search engines don’t render every page they come across.
Back in July 2016, Google said they found over 130 trillion documents , and it’s safe to say that since then, that amount of documents has increased massively.
Google simply doesn’t have the capacity to render all of these pages. They don’t even have the capacity to crawl all of these pages—which is why every website has an assigned crawl budget.
Websites have an assigned render budget as well. This lets Google prioritize their rendering efforts, meaning they can dedicate more time to rendering pages that they expect visitors to search for more often.
This in turn causes heavily-reliant JavaScript web pages to get indexed much slower than “regular” HTML pages. And if your web pages aren’t indexed, they can’t rank, and you won’t get any organic traffic.
Note: we keep talking about “search engines,” but from here on out, we’ll be focusing on Google specifically. Mind you, Bing—which also powers Yahoo and DuckDuckGo—renders JavaScript as well , but since their market share is much smaller than Google’s, we’ll focus on Google.
How does Google deal with JavaScript sites?
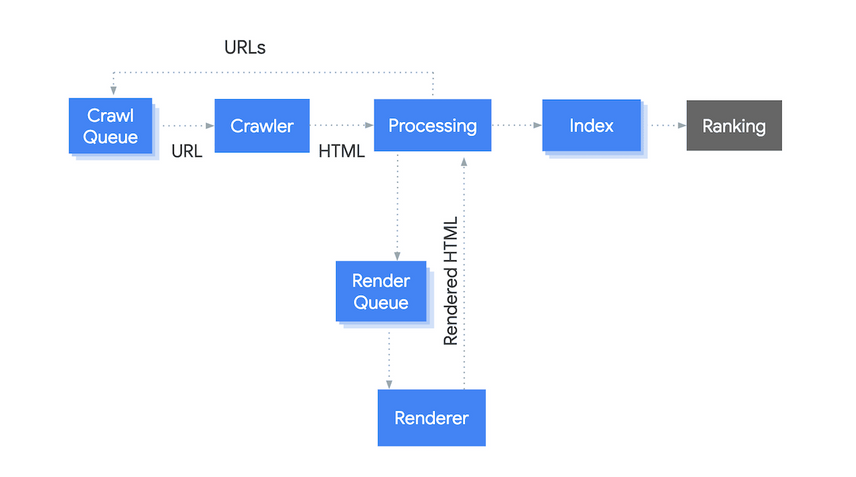
The illustration above explains Google’s processes from crawling to ranking conceptually. It has been greatly simplified; in reality, thousands of sub-processes are involved.
We’ll explain every step of the process:
- Crawl Queue: It keeps track of every URL that needs to be crawled, and it is updated continuously.
- Crawler: When the crawler (“Googlebot”) receives URLs from the
Crawl Queue, they request its HTML. - Processing: The HTML is analyzed, and
a) URLs found are passed on to theCrawl Queuefor crawling.
b) The need for indexing is assessed—for instance if the HTML contains ameta robots noindex, then it won’t be indexed (and will not be rendered either!). The HTML will also be checked for any new and changed content. If the content didn’t change, the indexIndex
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine’s index, users will not be able to find it.
Learn more isn’t updated.
c) The need for rendering is assessed, based on the page’s reliance on JavaScript. URLs that need to be rendered are added to theRender Queue. Please note that Google can already use the initial HTML response while rendering is still in progress.
d) URLs are canonicalized (note that this goes beyond the canonical link element; other canonicalization signals such as for example the XML sitemaps and internal linksInternal links
Hyperlinks that link to subpages within a domain are described as "internal links". With internal links the linking power of the homepage can be better distributed across directories. Also, search engines and users can find content more easily.
Learn more are taken into account as well). - Render Queue: It keeps track of every URL that needs to be rendered, and—similar to the
Crawl Queue—it’s updated continuously. - Renderer: When the renderer (Web Rendering Services, or “WRS” for short) receives URLs, it renders them and sends back the rendered HTML for processing. Steps 3a, 3b, and 3d are repeated, but now using the rendered HTML.
- Index: It analyzes content to determine relevance, structured dataStructured Data
Structured data is the term used to describe schema markup on websites. With the help of this code, search engines can understand the content of URLs more easily, resulting in enhanced results in the search engine results page known as rich results. Typical examples of this are ratings, events and much more. The Searchmetrics glossary below contains everything you need to know about structured data.
Learn more, and links, and it (re)calculates the PageRank and lay-out. - Ranking: The ranking algorithm pulls information from the index to provide Google users with the most relevant results.
So, in order for Google to understand a JavaScript-reliant web page, it needs to go through the full rendering phase, instead of being able to directly
- Forward URLs that need to be crawled to the
Crawl Queueand - Forward information that needs to be indexed to the
Indexphase. This makes the whole crawling and indexing process very inefficient and slow.
Imagine having a site with 50,000 pages, where Google needs to do a double-pass and render all of those pages. That doesn’t go down great, and it negatively impacts your SEO performance—it will take forever for your content to start driving organic traffic and deliver ROI.
Rest assured, when you continue reading you’ll learn how to tackle this.
Don't block CSS and JavaScript files to try and preserve crawl budget, because this prevents search engines from rendering your pages — leading to your pages being poorly understood by search engines and an inevitable poor SEO performance.
Best practices
Avoid search engines having to render your pages
Based on the initial HTML response, search engines need to be able to fully understand what your pages are about and what your crawling and indexing guidelines are. If they can’t, you’re going to have a hard time getting your pages to rank competitively.

Even though Google is getting better at rendering JavaScript, we shouldn't rely on it. Remember that JavaScript rendering by headless Chrome is much more resource-heavy for Google than to just parse HTML. If you use JavaScript on your website, make sure your content, images and links are served even with JavaScript disabled.
Include essential content in initial HTML response
If you can’t prevent your pages from needing to be rendered by search engines, then at least make sure essential content, such as the title and meta elements that go into the <head> section of your HTML, and important body content are loaded through JavaScript.
They should be included in the initial HTML response. This enables Google to get a good first impression of your page.
Tabbed content
Please note that this applies to tabbed content as well. For example on product detail pages, make sure content that’s hidden behind tabs is included in the initial HTML response and doesn’t require execution of JavaScript code to pull it in.
All pages should have unique URLs
Every page on your site needs to have a unique URL; otherwise Google will have a really hard time exploring your site and figuring out what your pages need to rank for.
Don’t use fragments in URLs to load new pages, as Google will mostly ignore these. While it may be fine for visitors to check out your “About Us” page on https://example.com#about-us, search engines will often disregard the fragment, meaning they won’t learn about that URL.
Did you know...
…that technical SEOs recommend using fragments for faceted navigation on places like eCommerce sites to preserve crawl budget?
Include navigational elements in your initial HTML response
All navigational elements should be present in the HTML response. Including your main navigation is a no-brainer, but don’t forget about your sidebar and footer, which contain important contextual links.
And especially in eCommerce, this one is important: pagination. While infinite scrolling makes for a cool user experienceUser Experience
User experience (or UX for short) is a term used to describe the experience a user has with a product.
Learn more, it doesn’t work well for search engines, as they don’t interact with your page. So they can’t trigger any events required to load additional content.
Here’s an example of what you need to avoid, as it requires Google to render the page to find the navigation link:
<a onclick="goto('https://example.com/schoes/')">Instead, do this:
<a href="https://example.com/shoes/">![Lidia Infante, Head of International SEO, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/051b016bd8b698105370febb3bacd2769caf06b1-560x560.jpg?dpr=1&fit=min&h=100&q=95&w=100)
When redesigning or making changes to a website, debugging any JavaScript issue is key before going live. If search engines can not render your navigation properly, you're missing out on a big opportunity to signal what your key pages are and how your site is structured.
Fixing it after you go live is an option, but you might find that your organic performance has already deteriorated.
One of the biggest issues we have seen recently is that developers use JavaScripts for links that Google can't crawl, such as
onclickor button type links, unless they've rendered the page. If you want Google to find and follow your links unchecked, they need to be presented in plain html, as good, clean internal linking is one of the most critical things for Google.
Send clear, unambiguous indexing signals
Google urges site owners to send clear and unambiguous crawling and indexing signals. Here we’ll look at several directives and explain why communicating clearly is more important than ever when we’re dealing with JavaScript SEO.
Meta robots directives
Overwriting your meta robots directives using JavaScript causes trouble. Here’s why:
- If you’ve got a
<meta name="robots" content="noindex, follow" />included in the initial HTML response that you’ve overwritten with aindex, followvalue using JavaScript, then Google will not find out about it because upon seeing thenoindex, they decide not to spend precious rendering resources on it.
On top of that, even if they were to discover that thenoindexhas been changed toindex, Google generally adheres to the most restrictive directives, which is thenoindexin this case. - But what if you do it the other way around, having
<meta name="robots" content="index, follow" />and then using JavaScript to change thatindextonoindex?
In that case, Google is likely to just index the page because it’s allowed according to the initial HTML response. However, only after the page has been rendered, Google finds out about thenoindexand removes the page from its index. For a (brief) period of time, that page which you didn’t want to be indexed was in fact indexed and possibly even ranking.
Canonical links
Overwriting canonical links equally makes mayhem.
In May of 2018 , John Mueller said: “We (currently) only process the rel=canonical on the initially fetched, non-rendered version.” and Martin Splitt said in November 2020 that this “undefined behaviour” leads to guesswork on Google’s part—and that’s really something you should avoid.
Injecting canonical links through JavaScript leads to the situation where Google only finds out about the canonical links after they’ve crawled and rendered your pages. We’ve seen instances where Google starts crawling massive amounts of personalized pages with unique URLs because the canonical link wasn’t included in the initial HTML response, but injected through JavaScript. This is a waste of crawl budget and should be avoided.
rel="nofollow" link attribute value
The same goes for adding the rel="nofollow" attribute value to links using JavaScript. Google’s crawler will just extract these links and add them to the Crawl Queue. They get crawled sooner than Google was able to render the page, resulting in the discovery of the rel="nofollow". Again, this is a waste of crawl budget and only leads to confusion.
The other way around, having the rel="nofollow" link attribute value present and removing it using JavaScript won’t work—similar to meta robots directives—because Google will adhere to the most restrictive directive .
Other directives
Don’t forget to include other directives in your initial HTML response as well, such as for instance:
- link rel="prev"/"next" attribute
- link rel="alternate" hreflang attribute
- link rel="alternate" mobile attribute
- link rel="amphtml" attribute

Error handling and serving correct status codes is often overlooked when auditing JavaScript sites, as automated crawlers frequently miss these. We've seen many JavaScript sites always return
200status codes, despite performing redirects or serving an error template. This can happen if the resource is being requested using JavaScript after the page returns a200while loading resources.Getting status codes wrong impacts crawling and indexing, and this prevents passing of authority. Ensure your routing returns accurate header responses. A common work-around for JavaScript sites is to redirect URLs to a specific
/404 pagethat returns the404response code.
Let search engines access your JavaScript files
Make sure you’re not accidentally preventing search engines from accessing your JavaScript files through your robots.txt file, resulting in search engines being unable to render and understand your pages correctly.
Remove render-blocking JavaScript
Render-blocking JavaScript is JavaScript code that slows down rendering of your web page. This is bad from a user-experience point of view, but also from an SEO point of view, as you want to make it as quick and painless as possible for Google to render your web pages. After all, it’s bad enough that they need to render your web pages already.
To avoid extra network requests, use inline JavaScript. On top of that, apply lazy loading as described in the next section.
Remove render-blocking CSS
We know we’re on the topic of JavaScript, but it’s also possible for CSS to be render-blocking. Optimizing these goes hand in hand, so look into this as well. For instance, you can inline some CSS that’s only sparsely used .

Inlining JavaScript can be a great solution for serving important resources to Googlebot fast by avoiding the network request latency. However this method is only advised for small critical scripts, as inlining large JS resources in the
<head>increases the time required for the bot to crawl the page. Since all resources are parsed in order of appearance in the code, it is also important to ensure that crucial page information like metadata and critical CSS files are not being delayed by inlined scripts and are placed near the top of the<head>element.
![Romain Damery, Sr. Director, Technical SEO at Amsive Digital, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/aff5d7cd63400c6e00d49168da322a42f28aadf7-400x400.jpg?dpr=1&fit=min&h=100&q=95&w=100)
What Googlebot cannot render well, it cannot index well so make sure that the content and links you want to be crawled are found in the rendered version of your page. For the content to get its full weight for ranking purposes, also ensure that it is "visible" on page load, without user interactions (scroll, click, etc.).
Optimizing for the various speed metrics ensures that the rendering process does not "time out", which would leave search engines with an incomplete picture of your page or worse of your entire site as the faster search engines can render your pages, the more they tend to be willing to crawl.
While optimizing for the critical rendering path and limiting JS bundle sizes help, also audit the impact of third-party scripts on your browser’s main thread as they can significantly impact performance. A sports car towing a trailer will still feel painfully slow.
Leverage code splitting and lazy loading
Imagine this situation: your homepageHomepage
A homepage is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more heavily relies on JavaScript, and all of your other pages make limited use of JavaScript. Then it’s very inefficient if you load all the “homepage-only” JavaScript files when any page on your site is requested.
So on top of that, apply code splitting to load the JavaScript that is needed right away, and lazy-load the rest. This enables your pages to quickly both load and become interactive.
Implement image lazy loading with loading attribute
Lazy-loading images is a great way to improve page load speed, but you don’t want Google to have to fully render a page to figure out what images are included.
With the introduction of the loading attribute , there’s no need to implement lazy-loading through JavaScript anymore. Chromium-powered browsers (Chrome, Edge and Opera) as well as Firefox offer native support for the loading attribute.
See below for an image that’s included through the loading attribute example:
<img src="/images/cat.png" loading="lazy" alt="Black cat" width="250" height="250">
By including images via the loading attribute, you get the best of both worlds:
- Search engines are able to extract the image URLs directly from the HTML (without having to render it).
- Your visitors’ browsers know to lazy-load the image.
Leverage JavaScript caching and use content-hashes
In order not to affect your website’s user experience, Google caches JavaScript aggressively. That’s great when your JavaScript code doesn’t change too often, but what if it does? Then you need to be able to let Google pull the newest version quickly.
Add a content-hash to your JavaScript file names, including file names such as:
main.2a846fa617c3361f.jsexample.117e1c5c1e1838c3.jsruntime.9bdf68f2f1992a3d.js
When your JavaScript code changes, the hash updates, and Google knows that they need to request it.
Don’t assume everyone has the newest iPhone and access to fast internet
Don’t make the mistake of assuming everyone is walking around with the newest iPhone and has access to 4G and a strong WiFi signal. Most people don’t , so be sure to test your site’s performance on different and older devices—and on slower connections. And don’t just rely on lab data; instead, rely on field data.
Rendering options
It’s clear by now that client-side rendering, entirely relying on the client (a browser or crawler) to execute the JavaScript code, negatively impacts the whole crawling, indexing, and ranking process.
But, besides the JavaScript SEO best practices we just covered in the previous section, there are additional steps you can take to prevent JavaScript from dragging your SEO performance down.
While there are lots of rendering options (e.g. pre-rendering) out there, covering them all is outside of the scope of this article. Therefore, we'll cover the most common rendering options to help provide search engines (and users!) a better experience:
- Server-side rendering
- Dynamic rendering
Server-side rendering
Server-side rendering is the process of rendering web pages on the server before sending them to the client (browser or crawler), instead of just relying on the client to render them.
This rendering process happens real-time, and visitors and e.g. Googlebot are treated the same. JavaScript code can still be leveraged and is executed after the initial load.
Pros
- Every element that matters for search engines is readily available in the initial HTML response.
- It provides a fast First Contentful Paint ("FCP").
Cons
- Slow Time to First Byte ("TTFB"), because the server has to render web pages on the fly.
Dynamic Rendering
Dynamic Rendering means that a server responds differently based on who made a request. If it’s a crawler, the server renders the HTML and sends that back to the client, whereas a visitor needs to rely on client-side rendering.
This rendering option is a workaround and should only be used temporarily. While it sounds like cloakingCloaking
Cloaking is a method which gives search engines the impression that a website carries content that is different to what users actually see.
Learn more, Google doesn’t consider dynamic rendering cloaking as long as the dynamic rendering produces the same content to both request types.
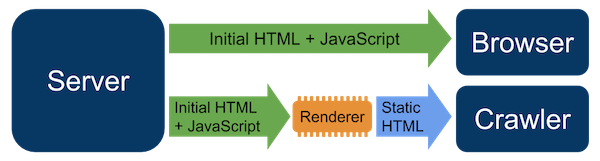
Pros
- Every element that matters for search engines is readily available in the initial HTML response sent to search engines.
- It’s often easier and faster to implement.
Cons
- It makes debugging issues more complex.

Don't take shortcuts for serving Google a server-side rendered version. After years of saying they could handle CSR (client-side rendered) websites perfectly, they are now actively promoting dynamic rendering setups. This is also beneficial for non-Google crawlers like competing search engines that can't handle JavaSscript yet and social media preview requests.
Make sure to always include basic SEO elements, internal links, structured data markup and all textual content within the initial response to Googlebot. Set up proper monitoring for detection of Googlebot (and others) since you don't want to take any risks. Google may add new IP ranges, new user agents or a combination of those two. Not all providers of pre-baked solutions are as fast as they should be in keeping up to date with identifying Googlebots.

When troubleshooting JavaScript issues, leverage your understanding of the order of operations used by Google. Imagine you're told that a site has implemented structured data markup on a set of pages but isn't seeing rich results.
Let's take a step back. Are these pages in the index? Structured data markup is an additional index processing phase. It's appearance requires clean technical signals during crawl, effective rendering, and unique value for the index.
Most JavaScript issues can be bucketed into a phase: crawl, render, or index.

Your job as an SEO is to make sure search engine bots understand your content. In my experience, it's a best practice to have a hybrid model where content and important elements for SEO are delivered as Server Side Rendered and then you sprinkle all the UX/CX improvements for the visitors as a Client Side Rendered "layer". This way you get best from both worlds, in organized manner. You can choose to combine rendering options. For the full spectrum of what's possible, check out these rendering options .
It's essential you separate content, links, schema, metadata, etc. from visitor improvements. That way you deliver greatness.
How do I check what my rendered pages look like?
You can use Google’s Mobile-Friendly Test to fetch and test a page, showing you what your rendered page would look like under the SCREENSHOT tab:
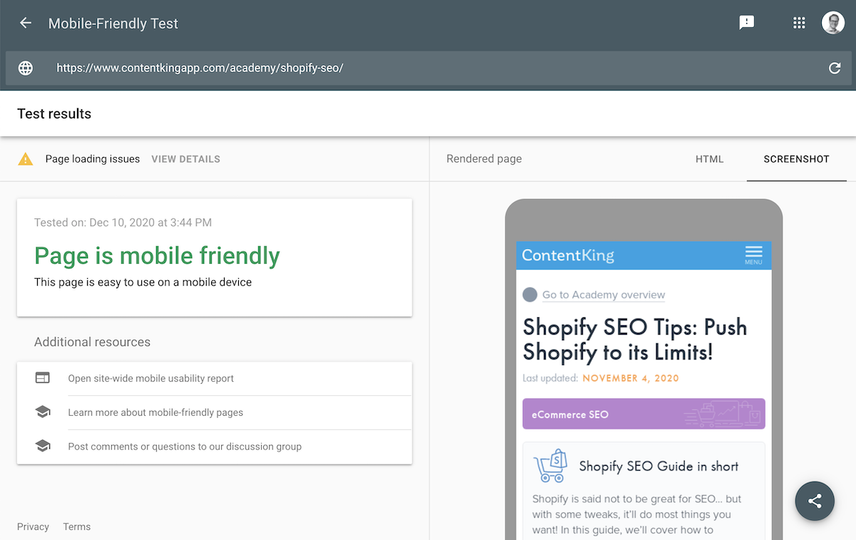
Don’t worry about your page getting cut off in the screenshot; that’s totally fine. You can also check what your rendered pages look like using Google Search Console’s URL Inspection tool.
Note that you can also access the HTML tab, which shows you the rendered HTML. This can be helpful for debugging.
![David Iwanow, Head of Search, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/5f4996305d653e2847aefbe94b078a20c02ab41c-200x200.jpg?dpr=1&fit=min&h=100&q=95&w=100)
Checking what rendered pages look like is a key task for any JavaScript SEO project, but the issue with Google Search Console is that it doesn't scale to checking hundreds, thousands or even hundreds of thousands of pages. I've used browser plugins, such as "view rendered source" by Jon Hogg but found that you only find real issues when you crawl thousands of pages.
Important page elements which you assumed would be shown in the rendered HTML, such as page titles, meta descriptions, internal links from menus and breadcrumbs are often not consistent across templates. Check your templates, specifically for differences between the initial HTML and the rendered HTML!
Render budget
At Google I/O ‘18, Google’s Tom Greenaway explained :
“The rendering of JavaScript power websites in Google Search is deferred until Googlebot has resources available to process that content.”
And as you can imagine, Google needs to set priorities in rendering, because not all websites are equal. Therefore, websites have an assigned render budget. This allows Google to dedicate more time to rendering pages that they expect visitors to search for more often.
This causes heavily JavaScript-reliant web pages to get indexed much slower than “regular” HTML pages, especially if such a website falls in the last rendering bracket.
What about social media crawlers?
Social media crawlersCrawlers
A crawler is a program used by search engines to collect data from the internet.
Learn more like those from Facebook, Twitter, LinkedIn, and Slack need to have easy access to your HTML as well so that they can generate meaningful snippets.
If they can’t find a page’s OpenGraph, Twitter Card markup or—if those aren’t available—your title and meta descriptionMeta Description
The meta description is one of a web page’s meta tags. With this meta information, webmasters can briefly sketch out the content and quality of a web page.
Learn more, they won’t be able to generate a snippet. This means your snippet will look bad, and it’s likely you won’t get much traffic from these social media platforms.
JavaScript SEO resources
- JavaScript: SEO Mythbusting w/ Martin Splitt and Jamie Alberico —a good foundation for understanding JS SEO, crawl budget, and rendering.
- Deliver search-friendly JavaScript-powered websites (Google I/O '18) —pretty accessible, and it serves as a useful foundation.
- Google Search and JavaScript Sites (Google I/O'19) —more technical but quite useful, as they walk you through the different steps in the crawling, indexing, and rendering process.
- What I learned about SEO from using the 10 most used JS frameworks —a good article, supported by a slide deck, that describes interesting take-aways.
- Understand the JavaScript SEO basics —documentation by Google's Martin Splitt.
- Rendering SEO manifesto – why JavaScript SEO is not enough —great guide by Bartosz Góralewicz.
- JavaScript & SEO: The Definitive Resource List —a massive collection of resources by Barry Adams, for when you're ready to take deep dive.
- The Cost Of JavaScript In 2018 by Addy Osmani —an easy to follow article on the cost of using JavaScript.
FAQs
Does Google crawler run JavaScript?
No, Google's crawlers don't run JavaScript. JavaScript rendering happens much further down the indexing pipeline, if Google determines it's required to get a good understanding of a page.
What do Google bots look for?
Google's crawlers continuously look for new content, and when they find it a separate process will process it. That process will first look at the initial HTML response. This response needs to include all of the essential content for search engines to understand what the page is about, and what relations it has to other pages.
Can Facebook render JavaScript?
No, they can't. Therefore, it's highly recommended to either use server-side rendering or dynamic rendering. Otherwise, Facebook (and other social media platforms) won't be able to generate a good snippet for your URL when it's shared.




