Crawled - currently not indexed: what does it mean and how to fix it?
The "Crawled - currently not indexed” error indicates that Google has already crawled these URLs, but hasn't indexed them yet.
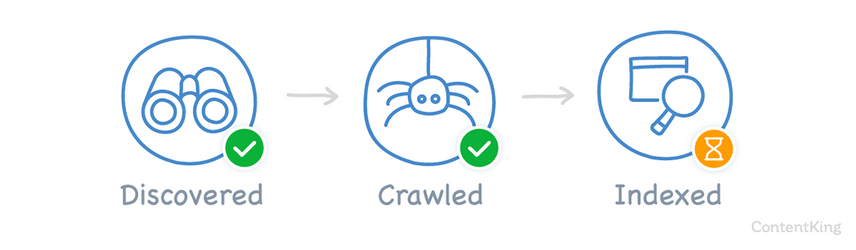
For most websites, this URL state is natural and will automatically resolve after Google's processed the URLs and added them to their index. To illustrate, this is where the URLs are in Google’s indexing process:
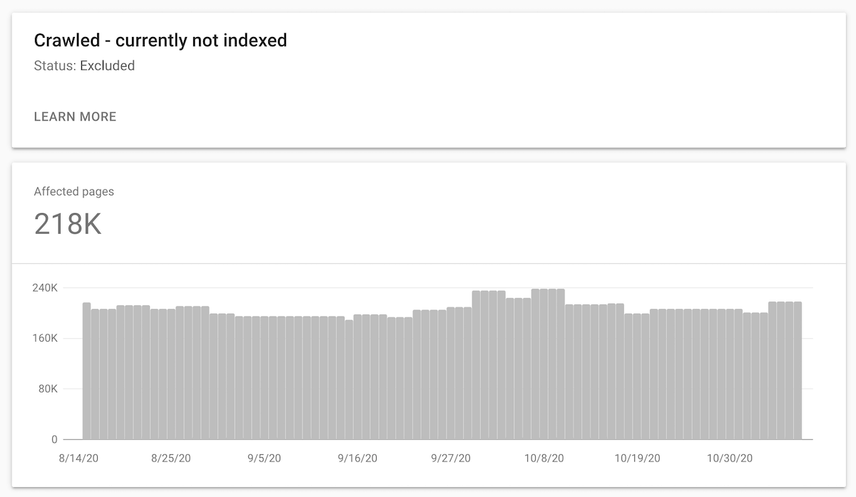
This error falls into the "Excluded" category, and looks like this in Google Search Console’s Index Coverage report:
Audit your site and find out right away!
If you're frequently encountering this issue on larger websites (10.000+ pages), this may be caused by:
- Poor internal link structure: these pages don't have enough links from. If you find important pages that you really want to rank with, add more internal links to it from pages higher in your website's architecture.
- Poor content quality: these pages may have been put on the back burner by Google, because they think the content's quality is lacking. Double-check whether your content is likely to satisfy user-intent, and adds more value than competing content on other sites.
- Duplication: these pages are (near) duplicates of other pages, and should actually be canonicalized.
- Domain Authority too low: if you've verified that step 1, 2 and 3 above aren't the issue it's likely that your domain authority is too low. You're publishing more content than Google is willing to index for your site. Gaining more backlinks will increase your domain authority.
Google will often surface your XML sitemaps, robots.txt and paginated pages in this error category as well. There's absolutely no need to take action on those.
Read the full Academy article to learn everything about Find and Fix Index Coverage Errors in Google Search Console
Share Article Details
About the authors

Steven van Vessum
Steven is Conductor's Director of Organic Marketing. This means he's involved in everything SEO, Content Marketing and Community related. Right where he wants to be. He gets a huge kick out of letting websites rank and loves to talk SEO, Content Marketing and Growth.


