Crawl anomaly: what does it mean and how to fix?
The “Crawl anomaly” error indicates that Google's had issues when requesting these URLs. They received response codes in the 4xx and 5xx range outside of the types they list within the Index Coverage report. To illustrate, this is where the URLs are in Google’s indexing process:
And here’s what this error looks like in Google Search Console’s Index Coverage report:
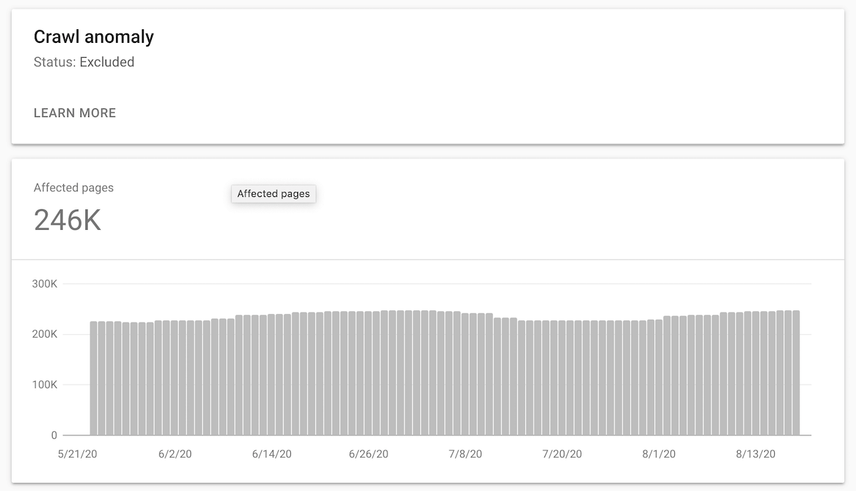
Double-check on URL level
You can double-check this by going to Coverage > Crawl anomaly and inspect one of the URLs listed, then under Crawl it'll say "Failed: Crawl anomaly" for the field Page fetch.
Typical pages that show up in this report
We often see "Members Only" and "Login" pages listed in the Crawl anomaly report with a HTTP status code 401, as they require login credentials.
How to diagnose and fix
Here's how to diagnose and fix the crawl anomaly issue:
- Go through the list of URLs, and verify that they are in fact not correctly loading. If it's just a hand full of URLs, you can use Google's URL inspection tool .
- If it's more, then we recommend doing spot checks with the inspection tool, and to add your site to ContentKing , because that enables you to quickly go through these URLs, and our platform will alert you about issues like these moving forward.
- If you're finding that the URLs work fine, the crawl anomaly could just be a temporary issue which should resolve automatically. If it doesn't, dig in further.
Important: Keep in mind that Google's crawlers may be receiving different responses than you are in your browser. When debugging, be sure to use Google's user agents .



