
Controlling Crawling and Indexing: the Ultimate Guide
Take control of the crawling and indexing process of your website by communicating your preferences to search engines.
This helps them to understand what parts of your website to focus on, and what parts to ignore. There's a lot of methods to do this, so when to use which method?
In this article we'll discuss when to use each methods, and we'll highlight the pros and cons.
Search engines crawl billions of pages every day. But they indexIndex
An index is another name for the database used by a search engine. Indexes contain the information on all the websites that Google (or any other search engine) was able to find. If a website is not in a search engine’s index, users will not be able to find it.
Learn more fewer pages than this, and they show even fewer pages in their results. You want your pages to be among them. So, how do you take control of this whole process and improve your rankingsRankings
Rankings in SEO refers to a website’s position in the search engine results page.
Learn more?
To answer that question, first we need look at how the crawling and indexing process works. Then we'll discuss all the methods you can put to work to control this process.
How does crawling work?
Search engines' crawlersCrawlers
A crawler is a program used by search engines to collect data from the internet.
Learn more are tasked with finding and crawling as many URLs as possible. They do this to see if there's any new content out there. These URLs can be both new ones and URLs they already knew about. New URLs are found by crawling pages they already knew. After crawling, they pass on their results to the indexer. Pages that search engines are allowed to crawl are often called crawlable.

Search engines can't rank what they can't crawl or haven't seen. That's why crawling and indexing are important topics.
How does indexing work?
The indexers receive the contents of URLs from the crawlers. Indexers then try to make sense of this content by analyzing it (including the links, if any). The indexer processes canonicalized URLs and determines the authority of each URLURL
The term URL is an acronym for the designation "Uniform Resource Locator".
Learn more. The indexer also determines whether they should index a pagePage
See Websites
Learn more. Pages that search engines are allowed to index are often called indexable.
Indexers also render web pagesWeb Pages
When you enter an internet address (a URL, e.g. https://login.1und1.de/) into a web browser, a webpage will appear.
Learn more and execute JavaScript. If this results in any links being found, these are passed back to the crawler.

Make sure your site is easily crawlable and crawl budget is not wasted. We know that Google has incredible crawling capacity, but especially on large eCommerce websites it really pays off to make sure Google's crawling and indexing the right pages. This improves relevance, conversion and ultimately revenue.
How to take control over crawling and indexing
Take control of the crawling and indexing process by making your preferences clear to search engines. By doing so, you help them understand what sections of your websiteWebsite
A website is a collection of HTML documents that can be called up as individual webpages via one URL on the web with a client such as a browser.
Learn more are most important to you.
In this chapter we'll cover all the methods and which to use when. We've also put together a table to illustrate what they can and cannot do.
First let's explain some concepts:
- Crawlable: are search engines able to crawl the URL?
- Indexable: are search engines encouraged to index the URL?
- Prevents duplicate content: does this method prevent duplicate content issues?
- Consolidates signals: are search engines encouraged to consolidate topical relevancy and URL authority signals, as defined by the URL's content and links?
Furthermore, it's important to understand what crawl budget is. Crawl budget is the amount of time search engines' crawlers spend on your website. You want them to spend it wisely, and you can give them instructions for that.

For large websites it can be a delicate balance to manage a search engine's crawl effort to ensure all the right pages are crawled and indexed, while not blocking too many pages at the same time. Ideally a well thought-out site structure prevents a lot of long term crawl issues, but sometimes the sledgehammer approach of robots.txt blocking can do the trick. I also like using rel=nofollow on specific links I don't want search engines to crawl, such as faceted navigation.
![Paul Shapiro, Head of Technical SEO & SEO Product Management, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/fd312eea58cfe5f254dd24cc22873cef2f57ffbb-450x450.jpg?dpr=1&fit=min&h=100&q=95&w=100)
Crawling and indexing is the crux of technical SEO. It's not something you need to worry about as much for smaller, basic websites. Google is fairly decent with that. But for larger, more complex websites, working to take control of crawling and indexing patterns becomes an essential part of SEO tasks, and can make all the difference.
Methods to control crawling and indexing
Crawlable | Indexable | Prevents | Consolidates | |
|---|---|---|---|---|
Robots.txt | ||||
Robots directives | ||||
Canonical | ||||
Hreflang attribute | ||||
Pagination attributes | ||||
Mobile attribute | ||||
HTTP authentication |
![David Iwanow, Head of Search, [object Object]](https://cdn.sanity.io/images/tkl0o0xu/production/5f4996305d653e2847aefbe94b078a20c02ab41c-200x200.jpg?dpr=1&fit=min&h=100&q=95&w=100)
Search engines are OK-ish at figuring out what pages to crawl and index, but often it's recommended to communicate your preferences regarding the crawling and indexing process to them. Then they know what pages to focus on and which pages to ignore during crawling, which subsequently leads to more focus during indexing and less junk pages getting indexed.
Robots.txt
The robots.txt file is a central location that provides basic ground rules for crawlers. We call these ground rules directives. If you want to keep crawlers from crawling certain URLs, your robots.txtRobots.txt
Robots.txt file is a text file that can be saved to a website’s server.
Learn more is the best way to do that.
If crawlers aren't allowed to crawl a URL and request its content, the indexer will never be able to analyze its content and links. This can prevent duplicate contentDuplicate Content
Duplicate content refers to several websites with the same or very similar content.
Learn more, and it also means that the URL in question will never be able to rank. Also, search engines will not be able to consolidate topical relevanceTopical Relevance
With search engines, topical relevance is mainly used in conjunction with backlinks (incoming links).
Learn more and authority signals when they don't know what's on the page. Those signals will therefore be lost.
An example for using robots.txt
A site's admin section is a good example of where you want to apply the robots.txt file to keep crawlers from accessing it. Let's say the admin section resides on: https://www.example.com/admin/.
Block crawlers from accessing this section using the following directive in your robots.txt:
Disallow: /admin
Can't change your robots.txt file? Then apply the robots noindex directive to the /admin section.
Important notes
Please note that URLs that are disallowed from being crawled by search engines can still appear in search results. This happens when the URLs are linked to from other pages, or were already known to search engines before they were made inaccessible through robots.txt. Search engines will then display a snippet like this:
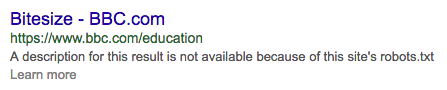
Robots.txt cannot resolve existing duplicate content issues. Search engines will not forget about a URL simply because they can't access it.
Adding a canonical URL or a meta robots noindex attribute to a URL that's been blocked through robots.txt will not get it deindexed. Search engines will never know about your request for deindexing, because your robots.txt file is keeping them from finding out.
The robots.txt file is an essential tool in optimizing crawl budget on your website. Using the robots.txt file, you can tell search engines not to crawl the parts of your website that are irrelevant for them.
What the robots.txt file will do:
- Keep search engines from crawling certain parts of your website, thereby preserving crawl budget.
- Keep search engines from indexing certain parts of your website – if there are no links to them.
- Prevent new duplicate content issues.
What the robots.txt file will not do:
- Consolidate relevancy and authority signals.
- Remove content that's already indexed*.
* While Google supports the noindex directive and will remove URLs from its index, it's not recommended to use this method as it's an unofficial standard. It's only supported by Google and not 100% fool proof. Only use it when you can't use robots directives and canonical URLs.

From experience, Googlebot can be very aggressive when crawling URLs if you leave it to figure things out on it's own. Anything that remotely looks like a URL in your source code can be crawled and I've seen them "try" URLs that don't appear to exist. For most sites, this probably isn't a big issue, but if your site is anything more than a few thousand URLs, you do need to think about controlling Googlebot and ensuring that they spend as much time as possible crawling the URLs that you care about.
Robots directives
The robots directives instruct search engines on how to index pages, while keeping the page accessible for visitors. Often it's used to instruct search engines not to index certain pages. When it comes to indexing, it's a stronger signal than the canonical URL.
Implementing robots directives is generally done by including it in the source using the meta robots tag. For other documents such as PDFs or images, it's done through the X-Robots-Tag HTTP header.
An example for the use of the robots directives
Say you have ten landing pages for Google AdWords traffic. You copied the content from other pages and then slightly adjusted it. You don't want these landing pages to be indexed, because that would cause duplicate content issues, so you include the robots directive with the noindex attribute.
Important notes
The robots directives helps you prevent duplicate content, but it doesn't attribute topical relevance and authority to another URL. That's just lost.
Besides instructing search engines not to index a page, the robots directives also discourages search engines from crawling the page. Some crawl budget is preserved because of this.
Contrary to its name, the robots directives nofollow attribute will not influence crawling of a page that has the nofollow attribute. However, when the robots directives nofollow attribute is set search engineSearch Engine
A search engine is a website through which users can search internet content.
Learn more crawlers won't use links on this page to crawl other pages and subsequently won't pass on authority to these other pages.
What the robots directives will do:
- Keep search engines from indexing certain parts of your website.
- Prevent duplicate content issues.
What the robots directives will not do:
- Keep search engines from crawling certain parts of your website, preserving crawl budget.
- Consolidate most of the relevancy and authority signals.
- Check out the ultimate guide to meta robots tag.
Canonical URLs
A canonical URL communicates the canonical version of a page to search engines, encouraging search engines to index the canonical version. The canonical URL can reference itself or other pages. If it's useful for visitors to be able to access multiple versions of a page and you want search engines to treat them as one version, the canonical URL is the way to go. When one page references another page using the canonical URL, most of its topical relevance and authority is attributed to the target URL.
An example for the use of a canonical URL
Say you have an eCommerce website with a product in three categories. The product is accessible via three different URLs. This is fine for visitors, but search engines should only focus on crawling and indexing one URL. Choose one of categories as the primary one, and canonicalize the other two categories to it.
Important notes
Make sure to 301 redirect URLs that don't serve a purpose for visitors anymore to the canonical version. This enables you to attribute all their topical relevance and authority to the canonical version. This also helps to get other websites to link to the canonical version.
A canonical URL is a guideline, rather than a directive. Search engines can choose to ignore it.
Applying a canonical URL will not preserve any crawl budget, as it doesn't prevent search engines from crawling pages. It prevents them from being returned for search queries as they are consolidated to the canonical version of the URL.
What a canonical URL will do:
- Keep search engines from indexing certain parts of your website.
- Prevent duplicate content issues.
- Consolidate most of the relevancy and authority signals.
What a canonical URL will not do:
- Keep search engines from crawling certain parts of your website, thereby preserving crawl budget.
- Check out the ultimate canonical URL reference guide.
Hreflang attribute
The rel="alternate" hreflang="x" link attribute, or hreflang attribute for short, is used to communicate to search engines what language your content is in and what geographical region your content is meant for. If you're using the same content or similar content to target multiple regions,hreflang is the way to go. It enables you to rank your pages in your intended markets.
It helps prevent duplicate content, so having two pages with the exact same content for the United Kingdom and United States is fine when you've implementedhreflang. Duplicate content aside, the most important thing is to make sure your content rhymes with the audience. Make sure your audience feels at home, so having (somewhat) different text and visuals for the United Kingdom and United States is recommended.
An example of using hreflang
You're targeting several English speaking markets using subdomains for each market. Each subdomain contains English content, localized for its market:
www.example.comfor the US marketca.example.comfor the Canadian marketuk.example.comfor the UK marketau.example.comfor the Australian market
Within each market you want to rank with the right page. Here's where hreflang comes in.
What the hreflang attribute will do:
- Help search engines rank the right content in the right market.
- Prevent duplicate content issues.
What the hreflang attribute will not do:
- Keep search engines from crawling certain parts of your website, thereby preserving crawl budget.
- Keep search engines from indexing certain parts of your website.
- Consolidate relevancy and authority signals.
- Check out the ultimate hreflang reference guide.
Pagination attributes
The rel="prev" and rel="next" link attributes, pagination attributes for short, are used to communicate the relationships among a series of pages to search engines. For series of similar pages, such as paginated blog archive pages or paginated product category pages, it's highly advisable to use the pagination attributes. Search engines will understand that the pages are very similar, which will eliminate duplicate content issues.
In most cases, search engines will not rank other pages than the first one in the paginated series.
What the pagination attributes will do:
- Prevent duplicate content issues.
- Consolidate relevancy and authority signals.
What the pagination attributes will not do:
- Keep search engines from crawling certain parts of your website, thereby preserving crawl budget.
- Keep search engines from indexing certain parts of your website.
- Check out the ultimate pagination reference guide.
Mobile attribute
The rel="alternate" mobile attribute, or mobile attribute for short, communicates the relationship between a website's desktop and mobile versions to search engines. It helps search engines show the right website for the right device and prevents duplicate content issues in the process.
What the mobile attribute will do:
- Prevent duplicate content issues.
- Consolidate relevancy and authority signals.
What the mobile attribute will not do:
- Keep search engines from crawling certain parts of your website, thereby preserving crawl budget.
- Keep search engines from indexing certain parts of your website.
- Check out the ultimate mobile attribute reference guide.
HTTP authentication
HTTP authentication requires users or machines to log in to gain access to a (section of a ) website. Here's an example of how it looks:
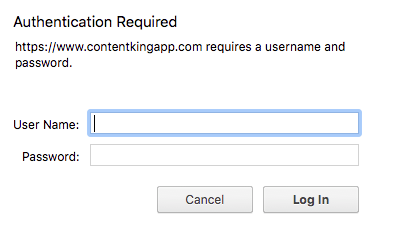
Without a username and password, you (or a robot) won't get past the login screen, and you won't be able to access anything. HTTP authentication is great way to keep unwanted visitors – both humans and search engine crawlers – out of for instance a test environment. Google recommends using HTTP authentication to prevent search engine crawlers from accessing test environments:
If you have confidential or private content that you don't want to appear in Google Search results, the simplest and most effective way to block private URLs from appearing is to store them in a password-protected directory on your site server. Googlebot and all other web crawlers are unable to access content in password-protected directories.
What HTTP authentication will do:
- Keep search engines from crawling certain parts of your website, thereby preserving crawl budget.
- Keep search engines from indexing certain parts of your website.
- Prevent duplicate content issues.
What HTTP authentication will not do:
- Consolidate relevancy and authority signals.
Fetch as search engines: putting yourself in their shoes
So how do search engine crawlers see your pages, and how do your pages render? Put yourself in their shoes by using their "Fetch and Render" tools.
Google's "Fetch as Googlebot" feature is most well known. It's located in Google Search Console and allows you to fill in a URL on your site and then Google will show you what their crawlers see on this URL, and how they render the URL. You can do this for both desktop and mobile. See below what this looks like:
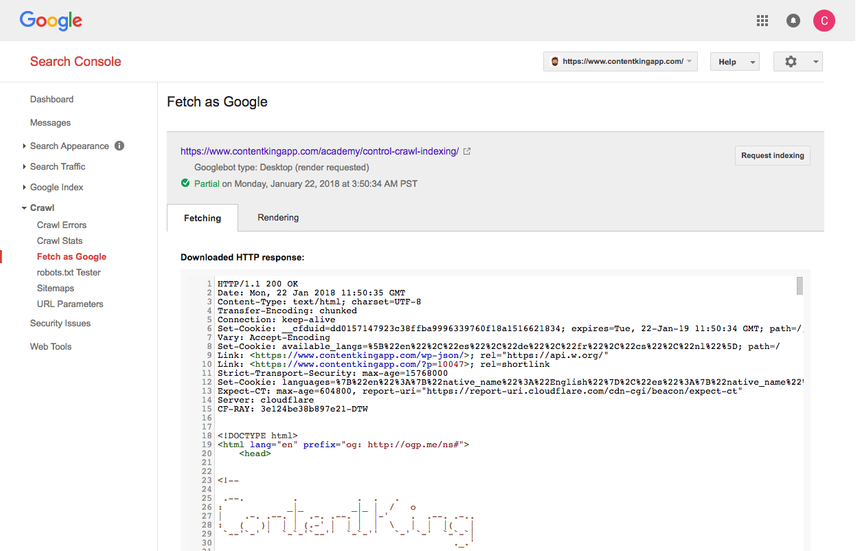
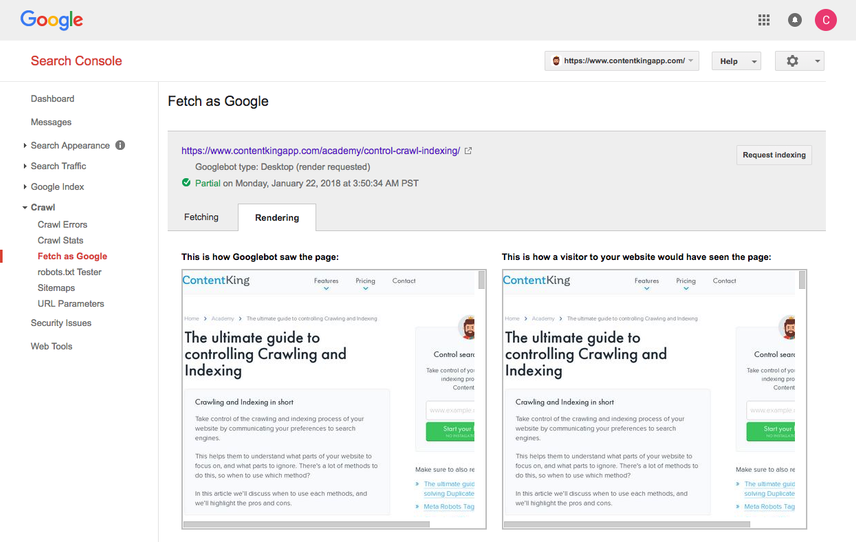
It's great for double checking whether URLs are responding as expected, but also to force push indexing the URL ("Request indexing"). Within seconds you can get a URL crawled and indexed. This doesn't mean its content is immediately processed and rankings are adjusted, but it does enable you to speed up the crawling and indexing process.
Other situations in which Fetch as Googlebot comes in handy
Fetch as Googlebot is not just useful for speeding up the crawling and indexing process of an individual URL, it also allows you to:
- Speed up discovery of entire new sections on your website
Fetch the URL from which the new sections are linked, and choose to "Request index" with the option to "Crawl this URL and its direct links" - Audit the mobile experience users have on your site:
Fetch a URL as "Mobile: smartphone". - Check whether 301-redirects are working correctly.
Fill in a URL and check the header response.
Notes:
- Situation 3 can more easily be done, in bulk within ContentKing.
- Google allows you to submit 500 URLs per month for Indexing.
- Google allows you to only submit 10 URLs per month for Indexing with all URLs linked from that URL getting crawled too.
- Bing has a similar tool, called "Fetch as Bingbot ".
Frequently asked questions about crawling and indexing
1How often does Google crawl my website?
Google Search ConsoleGoogle Search Console
The Google Search Console is a free web analysis tool offered by Google.
Learn more shares their crawl behavior with you. To check it out:
- Log on to Google Search Console and select a website.
- Head to "Crawl" > "Crawl Stats" and there you'll find out how often Google crawls your website.
If you're fairly tech savvy, you can find out how often Google's crawls your website by analyzing your website's log files).
It's worth noting that Google determines how often they should crawl your website using the crawl budget for your website.
2. Can I slow down crawlers when they're crawling my website?
Yes, you can do this using the crawl-delay robots.txt directive. Google won't listen to it though. If you want Googlebot to crawl slower than you have to configure this in Google Search Console. Regardless of the method, it's not recommended to throttle Google and Bing's crawlers. Their crawlers are smart enough to know when your website is having a hard time, and they'll check back later in that case.
3. How do I prevent search engines from crawling a website or page?
There's a few ways to go about preventing search engines from crawling parts of your website, or just specific pages:
- Robots.txt: can be used to prevent the crawling of an entire website, sections, and individual pages.
- HTTP authentication: can be used to prevent the crawling of an entire website, sections, and individual pages.
4. What does indexing a website mean?
It means actions are performed by a search engine to try to make sense of a website, in order to make it findable through their search engine.
5. Is my website indexable for search engines?
The best way to answer this is to create an account with ContentKing to evaluate how indexable your website is for search engines. As you've been able to read above, there are many ways to influence how search engines index your website.
6. How often does Google index my website?
As often as Google crawls your website. Its crawlers will pass on whatever they have found to the indexer, which takes care of indexing websites.
7. How long will it take Google to index my new website?
There's no single answer to this question, as it depends on the promotion of the new website. Promoting it speeds up the crawling and indexing process. If you do this well, a small website can be indexed with an hour. Alternatively, it can also take months to index an entirely new website.
Please note that having your website indexed by search engines doesn't mean your pages will start ranking high right off the bat. Achieving high rankings takes a lot more time.
8. How do I prevent search engines from indexing a website or page?
Search engines can be prevented from indexing a website or page via these methods:
- Meta Robots noindex tag: is a very strong signal to search engines not to index a page. It doesn't pass on relevance or authority signals to other pages.
- Canonical URL: is a moderately strong signal to search engines about what page to index, and to attribute relevance and authority signals too.
- HTTP authentication: will only prevent crawling and indexing of new pages from an SEO point of view. But it's a still general best practice to use HTTP authentication on test environments to keep unwanted search engines and users out of it.
- Robots.txt: can only be used to prevent the crawling and indexing of new pages.




